Match Boost improves enrichment coverage on sparse data
Faraday’s new Match Boost feature improves identity match rates—especially for sparse or single-identifier records—by tapping into additional data sources, enabling better predictions and broader omnichannel engagement.


Whether you're scoring leads, personalizing outreach, or building omnichannel campaigns with predictive modeling, it all starts with identity. And if you can't confidently link a record to a real person, everything downstream—predictions, engagement, outcomes—starts to break down.
Faraday already offers powerful identity resolution tools through the Faraday Identity Graph, which can do a lot with a little. Even sparse records like email-only or phone-only leads can often be matched and scored out of the box. But in high-stakes campaigns, every additional match counts and boosting that match rate, even slightly, can significantly impact your outcomes.
So to make sure that match rate is not just excellent, but as good as possible, we’ve introduced a new feature, called Match Boost. It taps into additional third-party identity sources to improve match rates even further, especially on partial or hard-to-match records. Whether you're trying to expand reach, improve prediction coverage, or support downstream workflows that rely on complete identity data, Match Boost helps you go beyond “good enough.”
Why match rate matters (more than ever) in 2025
3rd party predictive models like Faraday’s provide deeper insight than their first-party-only alternatives, but they still run on identity matching, and live or die by their ability to effectively match customer records to their external datasets. When individuals in your customer data are loaded into Faraday and recognized—that is, successfully matched to the Faraday Identity Graph, they’re enhanced with hundreds of rich datapoints. These new datapoints add fuel to your predictive models, allowing them to train on more information. Higher match rates mean:
- More records scored – fewer “unknown” rows languishing in the void.
- Sharper predictions – more signals per person, which means better lift curves.
- Omnichannel reach – physical addresses unlock direct mail, phone numbers power SMS, you get the idea.
- Cracking the cold start problem – enriches brand‑new or sparse lists so models have enough context to make accurate predictions from day one.
The trouble? Many datasets are hard to match: a newsletter signup with only an email, a warranty card with just a phone, a loyalty file missing addresses—those single‑identifier records can still slip through the cracks and if that happens, your baseline match step stalls and your models lose context.
Enter Match Boost
To solve this problem, we’re excited to share the latest feature added to the Faraday platform: Match Boost.
The Match Boost feature includes two distinct capabilities:
1. Recognition enhancement for better modeling
Match Boost increases the portion of your customer data that Faraday can recognize and enhance with datapoints from the Identity Graph. That means:
- More records matched
- More accurate and complete predictive models
- Better prediction coverage—no more “no-score” results
Behind the scenes, Faraday uses a network of data providers, submitting unmatched records from your datasets to retrieve additional identity data. With additional/updated identifiers, we’ll be able to match even more of your data to FIG.
2. Expanded identity enrichment for outbound engagement
Match Boost customers also gain access to identity data (like phone numbers and physical addresses) for deployment, enabling:
- Better channel coverage
- Omnichannel activation from day one

When would you use Match Boost?
So we get that Match Boost is powerful, but when, exactly is it the most useful? You’d reach for Match Boost when:
1. Your input data is extra sparse
Think single identifiers—like just an email or phone number. Faraday can often match these, but Match Boost increases the odds by tapping into third-party identity sources.
2. You need to engage on more channels
If you’re trying to run omnichannel campaigns but only have partial contact info, Match Boost helps fill in the gaps—like turning an email into a mailable household.
3. You’re trying to maximize model coverage
Predictive models work best when more people are matchable. Boosting match rates means fewer “unknowns” and stronger lift curves.
4. You want full enrichment—even for already-matched records
For clients with access to advanced features, Match Boost can run even on records already matched to Faraday’s graph, layering on additional identity details you wouldn’t get otherwise.
Getting set up
If you're interested in adding the Match Boost feature to your Faraday account, contact your account manager to get set up.
How it works in dashboard
- If your account has Match Boost enabled, you’ll see a checkbox labeled ‘enrich this dataset with additional identity data where possible’ when creating or editing a dataset.
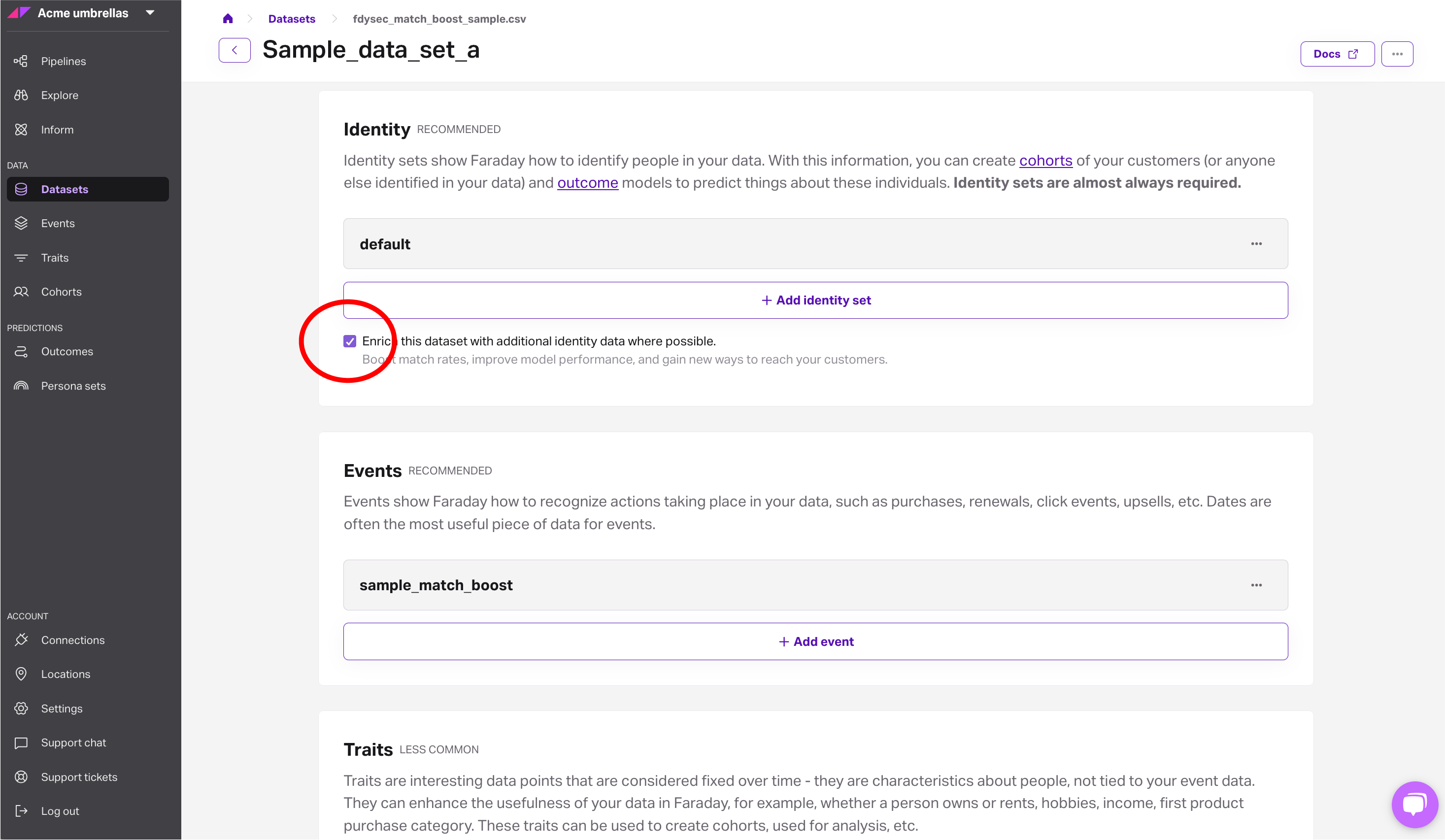
- Faraday runs its normal graph match process.
- Any unmatched records automatically flow through Match Boost.
- Additional identity data is resolved and returned.
- These new identifiers inform model training and improve prediction coverage.
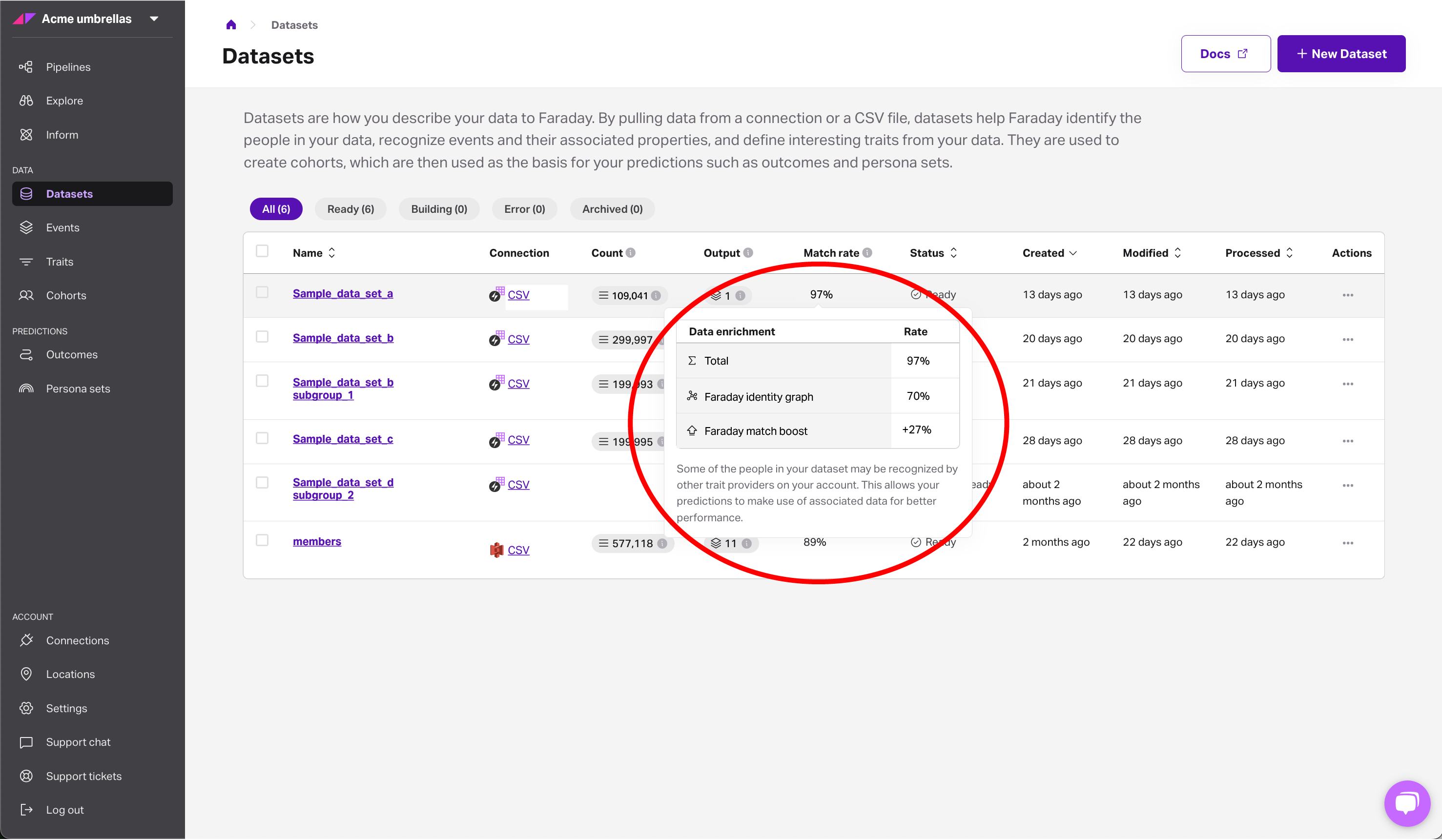
- You can view the impact directly in the dashboard—hover over the enrichment percentage in the dataset index view to see the lift.
- Whenever you make a new Deployment in Identified or Referenced mode, the output will automatically include identity data that was missing in your original dataset.
How it works in API
Faraday’s API users can enable Match Boost for a dataset by including it in the identity_providers array when making POST or PATCH dataset requests. This allows additional identity data to be resolved during the ingestion process, improving match rates and model performance.
{
...,
"identity_providers": [
{ "provider": "fig" },
{ "provider": "match_boost" }
]
}
We’ll be publishing a full API how-to next week, so keep an eye out if you’re looking to integrate this into your workflows programmatically.
Improve your predictive modeling, today
With Match Boost, your datasets stop freeloading and start pulling their weight. Contact your account manager to learn more, or if you’re not yet a customer, welcome! Come say hi to sales (they’re very friendly).
Let’s make every record count, together.
Ben Rose
Ben Rose is a Growth Marketing Manager at Faraday, where he focuses on turning the company’s work with data and consumer behavior into clear stories and the systems that support them at scale. With a diverse background ranging from Theatrical and Architectural design to Art Direction, Ben brings a unique "design-thinking" approach to growth marketing. When he isn’t optimizing workflows or writing content, he’s likely composing electronic music or hiking in the back country.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.