Understanding enrichment precision: what your match rate is actually telling you (and what it's not)
Match rate alone doesn’t tell you whether enriched data is actually useful, teams need to separate match precision, meaning person-level vs. address-level matching, from enrichment precision, meaning observed vs. imputed data. The right level of precision depends on the use case.


A high match rate is a vanity metric if you don't distinguish between where someone lives (address-level matching) and who they are (person-level matching). And even a perfect match doesn't guarantee useful enrichment — those are two independent dimensions of precision, and conflating them is one of the most common and costly mistakes teams make.
The two dimensions of data precision
There are two independent dimensions of precision in any data enrichment process: match precision and enrichment precision. They are not the same thing, and a strong score on one does not imply a strong score on the other.
-
Match precision describes how confidently a data provider recognizes the record you sent them. It has two levels: person-level matching (the provider has identified a specific individual — e.g., Jane Smith at 123 Main St, Unit 4B) and address-level matching (the provider has identified the household or residence, but not the specific person living there).
-
Enrichment precision describes the quality of the data being appended to that matched record. It also has two levels: observed data (the provider has actual, directly measured values for that person or household) and imputed data (the provider doesn't have the value directly, so they estimate it).
-
Imputation is the standard data science technique used when a value is missing. The system may look at everyone else known to live at the same fully qualified address — a spouse, an adult child, a roommate — take the values that are available for them, and average those to produce a best estimate. It's often better than returning nothing, but the resulting data is residence-level, even when the match itself was person-level.
These two dimensions combine into four possible outcomes. The quadrant below shows what each combination is good for:
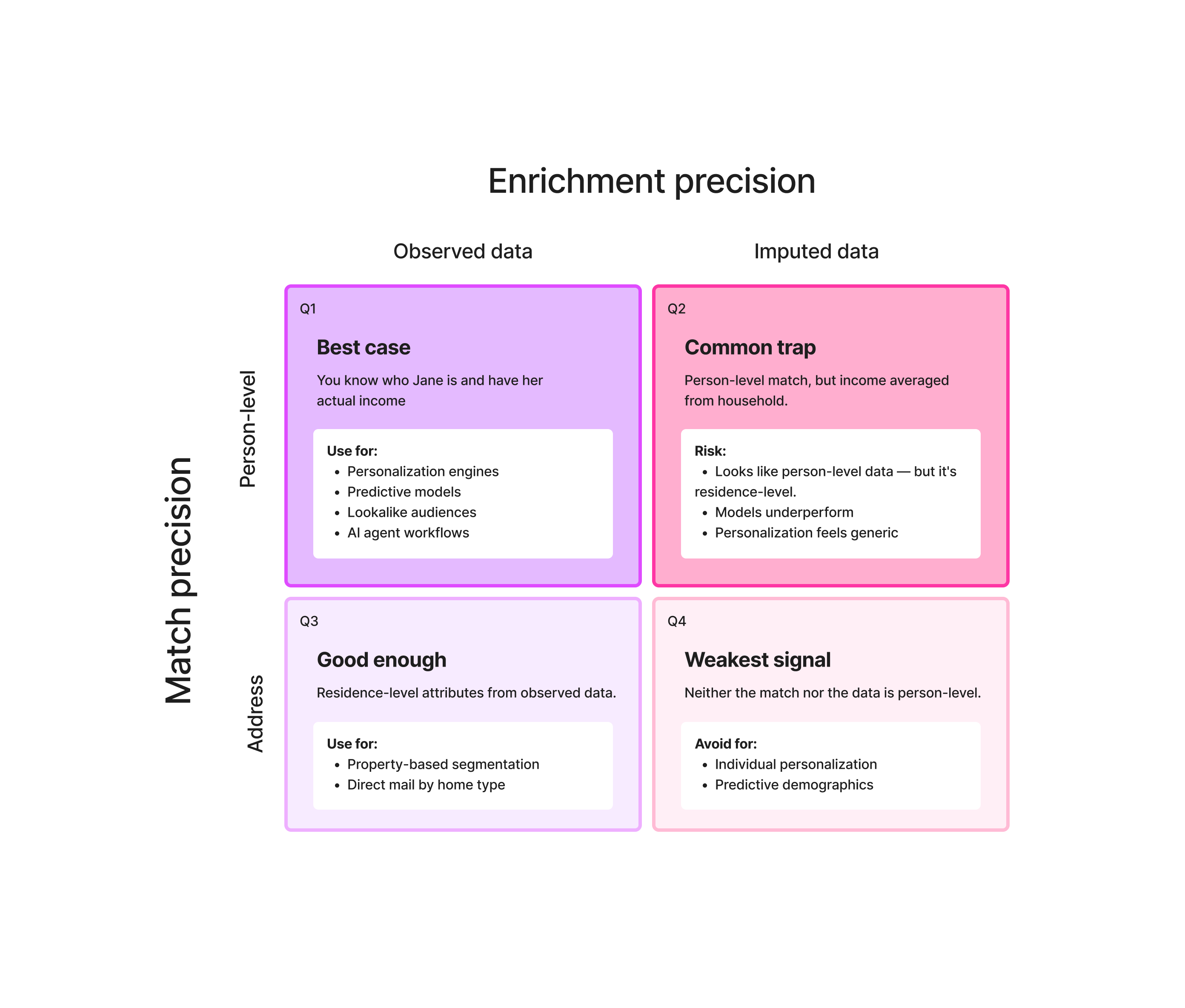
What matching precision actually means in practice
Both levels of matching are valid, depending on what you're doing. If you're running a direct mail campaign based on property characteristics — say, targeting homeowners with pools — address-level matching is perfectly fine. You care about the house, not the person. But if you're personalizing outreach based on individual behavior or demographics, person-level matching is what you actually need.
Most providers report a single "match rate" number without distinguishing between these levels. A 95% match rate sounds great — until you realize a significant portion of those matches are address-level, not person-level, and your personalization strategy depends on the latter.
What enrichment precision actually means in practice
Not all attributes are created equal. Some are naturally person-level — things like age, income, or purchase behavior. These describe an individual. Others are naturally residence-level — like bathroom count, square footage, or home value. These describe a property.
Here's a key insight: more precision isn't always better. If you ask for bathroom count for everyone in your customer base, you're going to get residence-level data — and that's exactly what you want, because bathroom count is fundamentally a property of the home, not the person. Asking for it at the person level wouldn't even make sense. The "right" level of precision depends on what the attribute actually describes.
When everything aligns perfectly, you get a person-level match with observed person-level data for a person-level attribute. You know who Jane is, and you have her actual income. That's the best case.
But data is inherently sparse. Even the best providers don't have every attribute for every person. So when a provider has matched Jane at the person level but doesn't have her income specifically, imputation kicks in — and the value you get back is residence-level, even though the match itself was person-level.
This is the distinction most teams miss: a person-level match does not guarantee person-level enrichment.
Why this matters for your strategy
If you're buying data to fuel AI models, personalization engines, or predictive analytics, the quality of your outputs depends entirely on understanding what went in. And "quality" here isn't just about volume or match rates — it's about the right kind of precision for your use case.
This connects to a broader problem we see across the industry: teams buy more data thinking it will solve their performance issues, when what they actually need is the right data at the right level of precision. A massive dataset with high match rates but mostly imputed enrichment data isn't necessarily more useful than a smaller dataset with genuine person-level attributes.
Here's a practical framework for thinking about it:
When address-level precision is fine:
- Direct mail campaigns targeting properties (not people)
- Geographic or neighborhood-level analysis
- Property-based segmentation (home value tiers, housing type)
When you need person-level precision:
- Individualized outreach or personalization
- Predictive models based on personal demographics or behavior
- Lookalike audience building based on individual customer profiles
- AI agent workflows that need to understand a specific consumer
Questions to ask your data provider:
- What percentage of my matches are person-level vs. address-level?
- For enriched attributes, how much of the data is directly observed vs. imputed?
- For the specific attributes I care about, are they naturally person-level or residence-level?
- How do you handle sparsity for the attributes that matter most to my use case?
Transparency builds better outcomes
Most data providers don't explain any of this. They give you a match rate, they give you enriched fields, and they let you assume the best. That works fine — until your AI model underperforms and you can't figure out why, or your personalized campaigns feel generic despite having "complete" customer profiles.
At Faraday, we think the answer is transparency. When you understand exactly what level of precision you're getting — for both matching and enrichment — you can make smarter decisions about how to use it. You can weight imputed data differently in your models. You can choose the right attributes for your use case. You can stop over-investing in data volume and start investing in data precision.
Because ultimately, the question isn't "how much data do I have?" It's "do I have the right data, at the right level of precision, for what I'm trying to do?"
Want to understand how Faraday handles matching and enrichment precision for your data? Grab a time to talk to one of our context consultants.
Ben Rose
Ben Rose is a Growth Marketing Manager at Faraday, where he focuses on turning the company’s work with data and consumer behavior into clear stories and the systems that support them at scale. With a diverse background ranging from Theatrical and Architectural design to Art Direction, Ben brings a unique "design-thinking" approach to growth marketing. When he isn’t optimizing workflows or writing content, he’s likely composing electronic music or hiking in the back country.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.