Deep dive: FIG v2 data catalog
Explore the new Faraday Identity Graph (FIG) v2 data catalog to access detailed attribute pages, visual data distributions, and technical metadata designed for marketers and data scientists.


This post is part of a series called Faraday Identity Graph that helps Faraday users understand how FIG works, and how they can use it to generate value for their business
We recently announced the biggest update to the Faraday platform ever: an overhauled version of the Faraday Identity Graph (FIG). FIG is the foundational dataset on which all other services at Faraday are built and if you want the big picture, check out our main announcement.
But today, I want to zoom in and talk about one specific, highly anticipated aspect of FIG v2: the data catalog.
Starting from scratch
Over the last decade, we’ve learned a lot about how to structure data, and we’ve been continuously improving that whole time. But for FIG v2, rather than continue to make incremental updates, we took those years of learnings and rebuilt the dataset from scratch—ensuring every attribute is standardized, strictly categorized, and crystal clear.
Nowhere is that rigor more obvious than in our new data catalog.
A better data dictionary
This new data catalog goes far beyond a standard data dictionary. It features an entire dedicated page for every single attribute in FIG v2.
Historically, a lot of this highly detailed data has only existed internally at Faraday and clients were required to go through their account management team to get these details. Now, for the first time, we are publishing it so that all of our users can get direct value out of it.
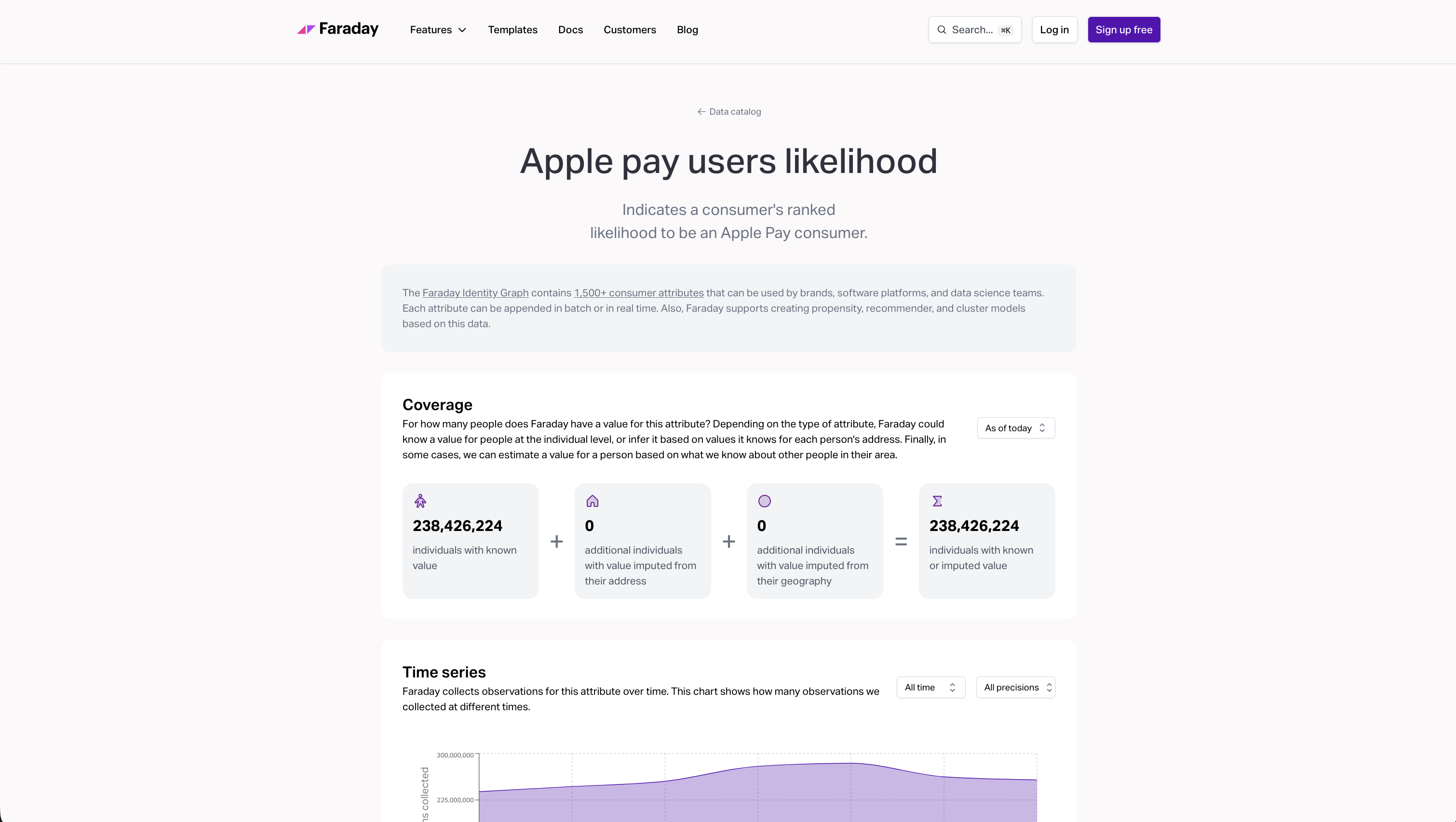
When you land on these new attribute pages, you won't just find basic metadata like names and descriptions. We are showing you the true depth of the data by surfacing the really important technical details and historical context you need to make decisions, including:
- Data distribution: Exactly how many people are observed in each category, or how a numerical attribute is distributed across a histogram.
- Technical properties: The API name, category, unit, data type, statistical type, allowed values, and deprecation status.
- Coverage breakdowns: Exactly how many individuals have a known value versus a value imputed from their address or geography.
- Data derivation: Whether a value was directly collected/observed, modeled, or survey-based — so you know exactly how each attribute was produced.
- Time series and contribution history: A look at how many observations we've collected over time and the authorities that contributed them.
- Directionality and interpretation: Guidance on how to use the data (e.g., how missing values should be interpreted—does a missing value mean "we don't know," or should you assume it's "false"?).
Built for marketers and data scientists alike
How you use this level of transparency really depends on what you're trying to build.
If you’re a marketer, let's say you’re looking for a specific piece of context to personalize an email campaign. In the past, finding that exact attribute usually meant digging through a dense, traditional data dictionary or—more likely—having to reach out to your account manager and wait for an answer. Now, you can skip the middleman, search the catalog yourself, and find exactly what you need to make a campaign feel bespoke.
If you're a data scientist, say using Faraday's data for internal modeling, things like data type and directionality matter immensely—they have a massive impact on the resulting accuracy of the models you're building. Instead of hunting for those specs, all of those crucial technical details are now front and center.
Easier to browse, more to discover
When you start searching through the new data catalog, you might notice the data feels much cleaner. By doing a massive amount of consolidation and normalization behind the scenes, we’ve made FIG v2 much easier to navigate. Better yet, that cleanup created headroom for us to bring in additional vendors and add entirely new attributes.
So go ahead and explore—there is a lot more context about American consumers waiting for you.
Interested in a specific data point? If you're looking for a particular attribute or curious about our coverage for a specific demographic, we’re happy to pull those details for you. Just send a note to your account management team directly.
What comes next
As we noted in our main announcement, FIG v2 is set to officially release in April. However, we are currently looking for beta testers to get in early. If you're interested in getting your hands on the new data catalog and taking it for a spin, reach out to your account management team to learn more.
And keep an eye out—we'll be dropping more deep dives into FIG v2 in the coming weeks!
Andy Rossmeissl
Andy Rossmeissl is Faraday’s CEO and leads the product team in building the world’s leading context platform. An expert in the application of data analysis and machine learning to difficult business challenges, Andy has been running technology startups for almost 20 years. He attended Middlebury College and lives with his wife in Vermont where he lifts weights, makes music, and plays Magic: the Gathering.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.