All blog posts
Product
Getting started with Faraday
From data to prediction: How Faraday works under the hood
Faraday turns your first-party customer records into privacy-safe, identity-resolved profiles, trains and validates machine-learning models on the enriched data, and then deploys transparent propensity scores (with explainability) that predict who’s most likely to do what next.



Nick Haggerty &
Zach Fu
on
This post is part of a series called Getting started with Faraday that helps to familiarize Faraday users with the platform
See our complete guide: What is the Faraday Identity Graph?.
When brands partner with Faraday, they aren’t just looking for a score; they need to understand the mechanics behind that score. A common question we receive is: "How exactly is the system acting upon our data?"
While the underlying math is complex, the process is straightforward: identity resolution and enrichment, model training and validation, and deployment. Here's how each step works.
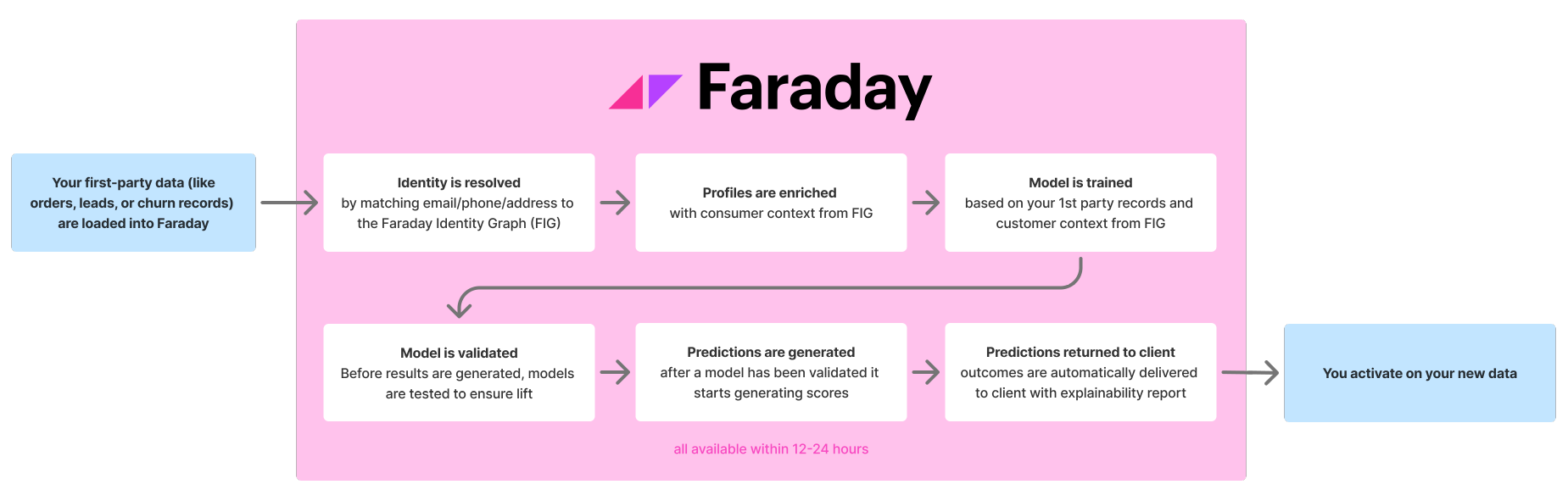
Identity resolution and enrichment
The process begins when your first-party data, whether it’s historical orders, lead lists, or churn records,is securely ingested into the Faraday system. But we don’t just store these rows; we resolve them.
We match your PII identifiers (emails, phone numbers, addresses) against the Faraday Identity Graph (FIG), a proprietary consumer dataset that contains over 1,400 attributes on more than 240 million U.S. adults and their households. This step is critical because your raw data is often fragmented or incomplete. By resolving identity first, we link your scattered records to rich, privacy-safe consumer profiles. This ensures our models are analyzing a complete person rather than a disconnected data point such as their address.
Once identity is resolved, the system enriches your data with relevant attributes from FIG, ranging from demographics to lifestyle interests. This enriched dataset becomes the foundation for modeling.
Model training and validation
Rather than relying on manual guesswork or generative AI such as ChatGPT, our models identify complex patterns in behavior that a human analyst might miss.
We first create a training set that includes your examples (customers who converted) and counter-examples (those who didn't). We then test various algorithms, such as Random Forests and Logistic Regression, on this enriched dataset. Each algorithm evaluates thousands of potential attribute combinations to find which approach best fits your data and business goals. We often combine multiple techniques to improve performance.
For instance, the model might discover that home ownership combined with recent purchase frequency and regional trends strongly predicts conversion for your business. This automated testing finds hidden signals that may take a human analyst months to find.
Before deployment, we validate the model on fresh data (holdout) to confirm the patterns hold up using methods, such as the 5-fold-cross-validation, to ensure model performance.
Deployment and transparency
Finally, the validated model generates actionable outputs that answer your business questions:, “Who is most likely to convert,” and “Which products will be most appealing to them.” The system then assigns a Propensity Score (percentiles from 1–100) to each subject for which one has been requested.
This process is transparent by design. Propensity scores are pushed directly back alongside explainability reports that details the factors driving each prediction, and how valid the predictions are. We don’t just deliver the prediction; we detail exactly why the prediction was made, giving your team full visibility into the model’s decision-making
Conclusion
In short, Faraday works by turning incomplete customer records into enriched profiles, then trains validated models that predict behavior. By combining secure identity resolution with the latest in machine learning, we ensure that the insights you get are not only accurate but fully explainable and ready to drive revenue.
Nick Haggerty
Nick Haggerty is Faraday's Business Enablement Lead, where he partners with customers to define goals, track ROI, and turn predictive insights into measurable business impact. With a background in performance marketing and digital media, Nick brings a practical, results-first approach to helping teams improve targeting, retention, and profitability. Outside of work, you’ll find him enjoying life in Vermont and chasing the next great problem to solve.
Zach Fu
Zach Fu is a Junior Data Scientist at Faraday, where he has been building data products that make predictions more interpretable and actionable. Trained in mathematics at Middlebury College, he contributes to various areas including data pipelines, client-facing tools, and model evaluation, using techniques ranging from statistical analysis to generative AI. Outside of work, he enjoys running half-marathons, listening to audiobooks, and practicing meditation.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.