All blog posts
Tech
Predictive data generates tangible value, and we can prove it
Faraday uses holdout testing to validate custom predictive data before you commit, ensuring it delivers real, measurable results.



Robin Spencer &
Ben Rose
on
A holdout evaluation is the industry-standard method data scientists use to validate predictive models: train on historical data, set aside a portion the model has never seen, then check whether the highest-scoring leads actually converted at higher rates. If they did, the model works.
If you're evaluating predictive data vendors, this is the test worth asking for. With tight budgets and increasing pressure to show ROI, you can't afford to bet on unproven tools or spend months figuring out if a vendor will live up to the promise. You need a way to separate legitimate predictive tools from the noise.
That's what our holdout evaluation does. It's not a methodology we invented — it's an industry standard used to validate custom predictive data, including propensity-to-buy scores used across lead buying, direct mail, and personalization.
Below we've outlined how it works and what to look for when evaluating whether it's delivering real value.
What is a holdout evaluation?
A holdout evaluation is a method for validating predictive models by comparing their predictions to real-world outcomes. We set aside a portion of recent conversion data—data the model has never seen before—and use it as an independent benchmark, against which predictions can be compared.
This "holdout set" acts as a real-world proving ground. It is untouched until after the predictive model has been trained.
Meanwhile, the rest of your historical data is combined with rich consumer data from the Faraday Identity Graph (FIG) (which includes over 1,400 data points on 240M+ U.S. adults and their households). We use this combined data to train the new predictive model.
Training a predictive model simply means finding patterns in historical conversions. In other words, what can we learn from your past customers to predict future outcomes? Once trained, the model generates predictions—scoring leads based on their likelihood to convert and only after these predictions are made do we compare them to the real conversion rates in the holdout set.
If the highest-scoring leads actually convert at higher rates than lower-scoring ones, the model is validated as accurate and reliable.
Holdout evaluations ensure predictive models aren't just theoretical—they work in the real world, using real data, to deliver real results.
How holdout validation works at Faraday
We've streamlined this validation process to be transparent and straightforward:
-

Step 1: Set aside a holdout group
We start with your recent lead conversion data. Before any processing occurs, we reserve a portion of your most recent leads as a "holdout set"—data that the model will never see during training. This ensures we have an independent benchmark for evaluating predictions.
-

Step 2: Enrich with consumer data
With the holdout set reserved, we then combine remaining data with Faraday's built-in consumer data sourced from the Faraday Identity Graph (FIG). This expanded dataset provides a deeper view into key predictive signals, like property and demographic information, life events, buying habits, and more.
-
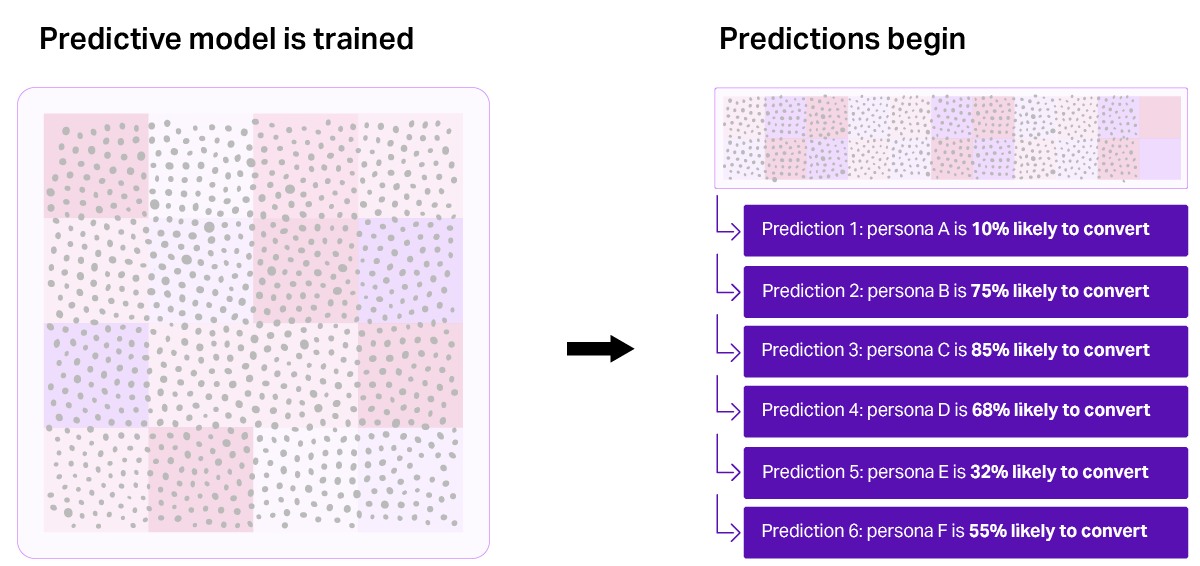
Step 3: Train the model and score leads
Using this enriched dataset (excluding the holdout set), we train a predictive model to identify patterns in conversion behavior—learning from consumer signals, demographic data, and behavioral patterns.
Once the model is trained, it scores each lead based on its likelihood to convert, generating a ranked list of opportunities—from high-value leads to those less likely to convert.
-
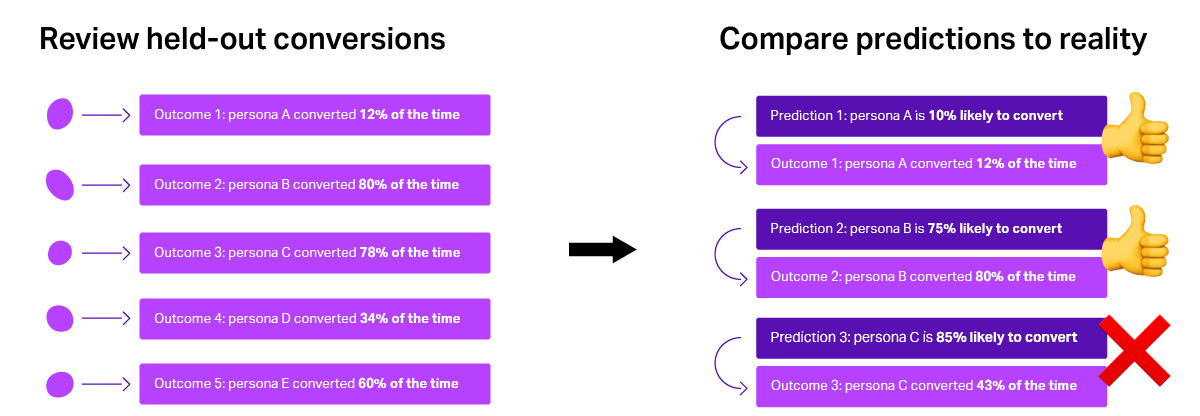
Step 4: Compare predictions to real outcomes
Finally, we put the model to the test: we compare its predictions against the real outcomes in that untouched holdout set. If the highest-scoring leads don't convert at significantly higher rates, we go back to the drawing board.
How to know if a holdout validation was successful
A holdout validation succeeds when predicted scores align with actual conversion rates across segments. Look for these three signs:
-
Clear correlation between predicted probability and actual conversion rates
The model's predicted likelihood to convert should directly align with the actual conversion rates. If the predictions are accurate, high-probability leads should convert at a noticeably higher rate than lower-probability ones. -
High-scoring leads convert at significantly higher rates
The top-scoring leads should consistently perform better than those ranked lower. This demonstrates that the model is identifying truly valuable leads. -
Consistent performance across different customer segments
The model should show reliable results across various segments—whether you're targeting different demographics, regions, or other customer profiles. If the model works well across a broad set of data, it proves its reliability and scalability.
When a model meets these criteria, it's ready to generate custom predictive data points—whether that means optimizing lead buying, refining your direct mail strategy, or enhancing your email personalization approach.
Questions you should ask us
We want you to push us on what matters most for your business. Here are key questions to evaluate if we're the right fit:
-
How does this model's performance compare to the lift you are seeing with similar businesses in our industry?
While we can't share client specifics, we can provide insight into broader trends and expected performance benchmarks.
→ Why this matters: Understanding industry benchmarks helps you gauge whether custom predictive data is truly a competitive advantage for your business.
-
How much historical data do we need for reliable predictions?
The answer varies by business model and conversion volume. We'll help determine whether you have enough data—or how to supplement it if needed.
→ Why this matters: Predictive models work best when trained on strong data. Knowing the threshold for reliability ensures you're making data-driven decisions with confidence.
-
What happens if the model doesn't perform as expected?
We have a structured iteration process to refine models when necessary, ensuring they reach meaningful predictive power.
→ Why this matters: No model is perfect on the first run. Understanding the process for continuous improvement ensures long-term success.
-
How will this integrate with our existing marketing stack?
We'll provide technical specs, discuss implementation timelines, and outline the resources needed to get up and running.
→ Why this matters: Seamless integration means faster time-to-value and less friction in your workflow.
Why holdout evaluations work
Holdout evaluations work because they test a model against data it has never seen — making it impossible to game the results. Any predictive data vendor can show you strong in-sample performance. Holdout testing is the check that confirms those patterns hold in the real world.
At the end of the day, three things matter to us:
-
Confidence before commitment:
You see proof before you commit -
Higher marketing efficiency: Your marketing dollars go to the leads most likely to convert
-
Stronger sales performance: Your sales team focuses on opportunities worth their time
If the validation doesn't show meaningful lift, we'll tell you. If it does, we'll quantify exactly what that means for your business.
Interested in generating value you can trust? Talk to a Context Consultant.
Frequently asked questions
What's the difference between a holdout evaluation and an A/B test?
A holdout evaluation validates that a predictive model works—it confirms that high-scoring leads actually convert at higher rates before you commit to anything. An A/B test measures the impact of a decision you've already made (like sending a campaign to scored vs. unscored leads). Faraday runs the holdout evaluation first so you have confidence in the model itself, not just the downstream campaign.
Do I need a large dataset for holdout testing to be meaningful?
Not necessarily. The threshold varies by industry and conversion volume. In many cases, a few months of lead and conversion history is enough to build a reliable model. We'll tell you upfront if your data isn't sufficient—and if it's borderline, we can discuss ways to supplement it with data from the Faraday Identity Graph.
What happens to my data during the validation process?
Your first-party data is used solely to train and validate the predictive model—it is never shared with other clients or used to enrich Faraday's broader data assets. The holdout set is kept completely separate from training and is only used as an independent benchmark after predictions have been made.
Robin Spencer
Robin Spencer is Faraday’s COO, leading all of our client-facing teams—from sales to customer success. Her mission is simple: help consumer businesses uncover where data can meaningfully improve (and profitably accelerate) the customer journey. Robin brings experience from Accenture, Google, and Clearbit (acquired by HubSpot), where she focused on using data to drive real, measurable business outcomes. When she’s not geeking out about data and operational strategy, you’ll find her tending her cut-flower garden, knee-deep in a creative project, or wandering in the woods nearby.
Ben Rose
Ben Rose is a Growth Marketing Manager at Faraday, where he focuses on turning the company’s work with data and consumer behavior into clear stories and the systems that support them at scale. With a diverse background ranging from Theatrical and Architectural design to Art Direction, Ben brings a unique "design-thinking" approach to growth marketing. When he isn’t optimizing workflows or writing content, he’s likely composing electronic music or hiking in the back country.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.