Context engineering and demographic data
Just as code copilots like Claude Code use tools like vector search to pick out relevant code (saving attention for writing code), consumer-facing AI agents should use predictive models to pick relevant demographic signals (saving attention for conversation and decision-making).


While there are 1,400+ demographic features available per American adult (from companies like Faraday), feeding all this raw data to an AI agent would overwhelm its "attention budget" - the limited cognitive capacity LLMs have to process context. Anybody who has used a code copilot like Cursor or Claude Code knows the feeling when its attention has wandered... after too much information, the LLM is distracted, not helpful, pissed off, stuck up a creek without a paddle. This is because of attention scarcity:
LLMs have an “attention budget” that they draw on when parsing large volumes of context. Every new token introduced depletes this budget...
Anthropic's Applied AI team recently wrote a short essay about the evolution from "prompt engineering" to "context engineering". The upshot is that you must continuously manage the information available to the LLM, keeping it focused by discarding unnecessary tokens but keeping "high-signal" tokens. Advanced AI agents like Cursor and Claude Code are rapidly getting better at this. It's much harder to tire them out now, thanks to strategies like:
- Tools - using vector search and
grepto find only relevant code, instead of reading the whole codebase. - Sub-agents - "sub-agents [handling] focused tasks with clean context windows [returning] condensed, distilled summar[ies] of [their] work."
- Compaction (compression) - "the practice of taking a conversation nearing the context window limit, summarizing its contents, and reinitiating a new context window with the summary" - often with the output of the tools or sub-agents.
This is relevant to my industry, demographic data and customer behavior predictions, because the amount of data available about every American adult - at least 1,400 features are available from Faraday alone - would easily overwhelm most LLM attention budgets. If you want to build AI agents that interact with American consumers and take advantage of third party data, you need to keep the signal while discarding the rest.
Let's detail 3 ways to do context engineering with demographic data. The upshot is to use quantitative methods as tools - really, as deterministic sub-agents - to compress the surfeit of raw demographic features into high-signal tokens and maximize the attention budget left over for AI agents to do their job:
Decision tree models
Decision tree models compress thousands of demographic features into a single propensity score by learning which combinations of features predict a specific outcome. They work by recursively splitting the population based on feature values—much like a flowchart—to find patterns that distinguish people who achieve an outcome from those who don't. Instead of forcing an AI agent to reason about every demographic detail, the model distills this complexity into one number that captures everything relevant to the prediction.
The input is historical examples: people who converted versus those who didn't, along with demographic and behavioral features describing them. The output is a percentile score (0-100) or probability for each person, indicating how likely they are to achieve the outcome. This compression is dramatic—from potentially 1,400 input features per person down to a single score that the agent can easily incorporate into its decision-making.
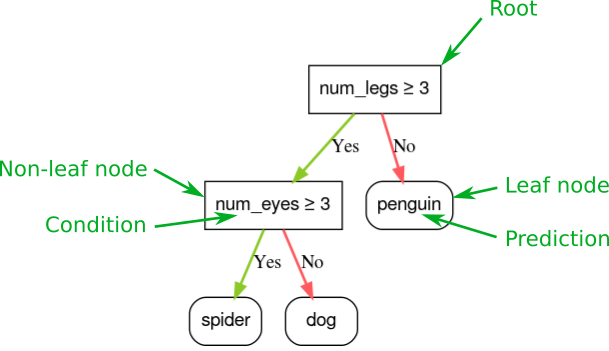 Decision trees efficiently compress thousands of demographic datapoints into high-signal tokens for LLMs (source: Google ML)
Decision trees efficiently compress thousands of demographic datapoints into high-signal tokens for LLMs (source: Google ML)
Decision trees give you numeric scores and lift that can go straight into your context:
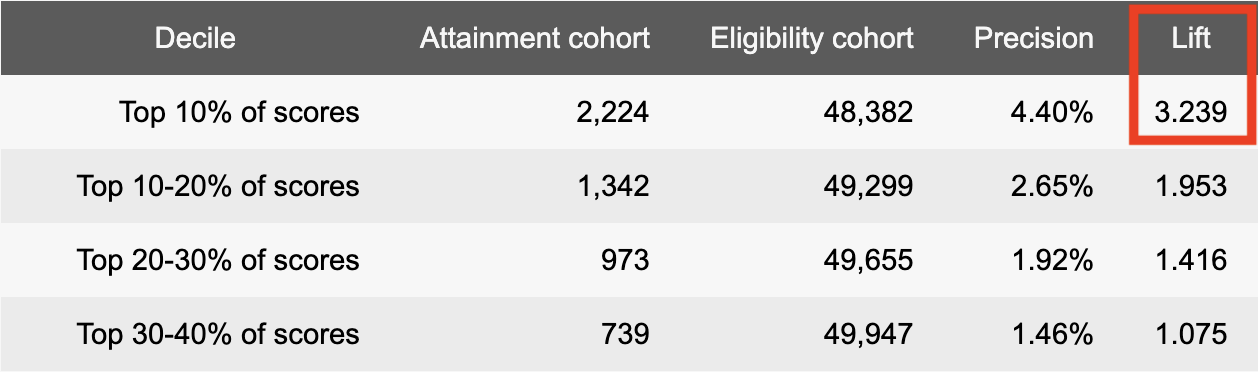 Help the LLM understand how convinced the user is (source: Faraday blog)
Help the LLM understand how convinced the user is (source: Faraday blog)
Consider a credit union building an AI agent to help members with financial planning. Without propensity models, the agent would need to process 1,400 demographic fields per member every time it considers whether to recommend opening a savings account. With a decision tree model, the agent simply receives a score indicating each member's likelihood to open an account, preserving its attention budget for actual conversation and advice.
Recommender systems
Recommender systems compress interaction history—purchases, clicks, views—into ranked predictions of which product or action comes next. These systems analyze the matrix of who-interacted-with-what across your entire customer base to find latent patterns: "people who bought A and B tend to buy C next." Instead of an AI agent processing raw transaction logs and product catalogs to figure out what to recommend, it receives a pre-computed ranked list that captures all that complexity.
The input is a transaction or interaction matrix (rows are people, columns are products or actions) plus any product metadata. The output is a ranked list of recommendations for each person—typically the top 5-10 options most likely to resonate. This compression is especially powerful because it captures collaborative filtering patterns (what similar people liked) without forcing the agent to analyze the entire interaction history every time.
 Recommenders use matrix factorization to efficiently compress product affinity and transaction history into high-signal tokens for LLMs (source: Google ML)
Recommenders use matrix factorization to efficiently compress product affinity and transaction history into high-signal tokens for LLMs (source: Google ML)
Imagine an e-commerce site building an AI shopping assistant. Instead of the agent analyzing every past purchase across thousands of products to determine what to suggest next, it receives "most likely next 5 products: [Product A, Product B, Product C, Product D, Product E]" and can focus its attention on how to present these recommendations conversationally based on the current chat context.
Cluster models
Cluster models group similar people together and identify the defining characteristics of each group, compressing individual-level variation into persona-level patterns. Rather than treating each consumer as a unique snowflake across thousands of attributes, clustering finds natural segments where people share meaningful similarities. An AI agent can then work with a handful of personas instead of reasoning about every individual's complete demographic profile—a massive reduction in cognitive load.
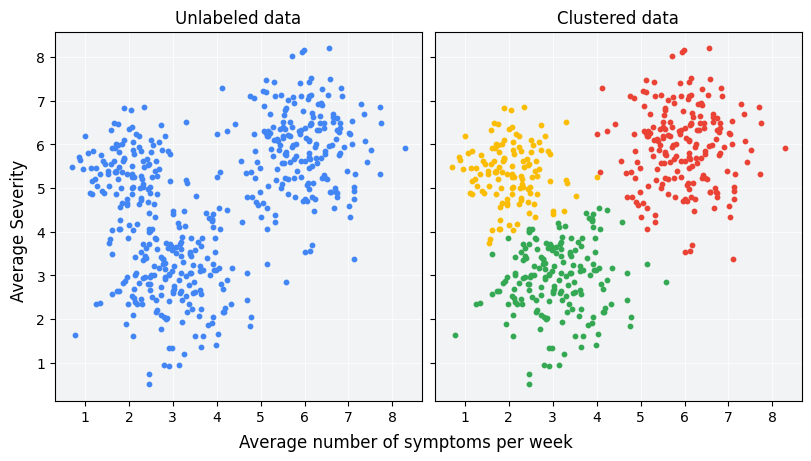 Don't tell your LLM all the dots... tell it the cluster (source: Google ML)
Don't tell your LLM all the dots... tell it the cluster (source: Google ML)
The input is your customer population with demographic and behavioral features. The output is typically 3-7 personas, each with defining characteristics and a label for every individual indicating which persona they belong to. For example, a model might identify distinct groups like "Budget-Conscious Families" and "Premium Singles," automatically determining which datapoints (income, household size, urban vs. rural) meaningfully distinguish these personas.
Consider a subscription service building an AI agent for customer support. Instead of the agent processing each customer's unique demographic and usage profile from scratch, it receives "this customer belongs to the Budget-Conscious Families persona" and can immediately apply relevant context about typical concerns, preferences, and communication styles for that segment. The agent's attention is freed up to focus on the specific support issue rather than figuring out who this customer is.
Faraday implementation notes
For readers interested in how these compression techniques are implemented in practice, here's how Faraday handles each approach:
Decision tree models: Faraday Outcomes handles this compression using multiple algorithms including random forests and gradient boosted trees. The system trains separate models for different customer lifecycle stages (how long someone has been in the sales funnel), handles both vendor-enriched demographic data and customer-only data, and applies fairness adjustments to ensure protected demographic groups aren't disadvantaged by the predictions.
Recommender systems: Faraday Recommenders uses a two-stage approach: matrix factorization finds collaborative filtering patterns, then propensity models (similar to Outcomes) refine those recommendations using demographic data. The system handles cold-start scenarios (new customers with no purchase history) by falling back to demographic-based predictions, and adapts to different data availability levels—working whether you have rich behavioral data or just basic customer information.
Cluster models: Faraday Persona Sets implements this using k-means++ clustering. The system automatically selects the optimal number of groups (balancing too few vs. too many personas), removes outliers before clustering to prevent extreme cases from distorting the personas, and identifies which specific datapoints distinguish each persona—importantly, not forcing every datapoint to matter when some simply don't differentiate between groups. It also builds lifetime value predictions for each persona, helping prioritize which segments deserve more attention.
Conclusion
When you use AI copilots like Cursor or Claude Code, you can feel them efficiently quantifying and summarizing your code base. They use tools like vector search and grep to pull out the high signal tokens and leave themselves lots of attention budget to write code. This is similar to what's necessary with AI agents that want to use third party data to interact with consumers. You have to selectively compress information about the consumers; decision trees, recommenders, and clusters are a simple quantitative way to do this.
Seamus Abshere
Seamus Abshere is Faraday’s Co-founder and CTO (and serves as CISO), leading the technical vision behind the company’s consumer modeling platform. At Faraday, he focuses on building an API for consumer modeling and the infrastructure that helps customers turn first-party data into more actionable predictions. Before Faraday, Seamus was an Engineering Director at Brighter Planet. He studied Anthropology and Computer Science at Princeton University and is based in Burlington, Vermont.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.