How Faraday unifies your data with the Faraday Identity Graph for advanced identity resolution
Faraday unifies your data with rich third-party data and applies advanced identity resolution techniques to reveal panoramic views of your customers and leads.


See our complete guide: What is the Faraday Identity Graph?.
What is identity resolution?
Identity resolution is the process of taking all of the files and databases of people data in your organization and figuring out "who is who" so that you can unify individual records into a single entity. For example, one database might have email, and another database might have street address; how do you connect them? Identity resolution is the answer.
Within identity resolution, there are two broad categories: known identity and anonymous (unknown) identity. Known identity is figuring out the email, phone number, and/or street address of someone. If you have known identity, you can find someone in the real world. Anonymous identity is defining some IP address, device ID, browser fingerprint, or cookie that represents a person without actually knowing who they are in the real world. In either case, you’re trying to get a join key or universal ID that lets you combine data from different sources across time.
How does identity resolution work? In a few different ways:
- You explicitly collect known identifiers like email in web forms or addresses in orders/transactions.
- You implicitly collect anonymous identifiers like IP addresses, cookies, as they browse.
- You stitch together known and anonymous identifiers when people click links in emails, log in, enter billing and shipping data, etc.
- You connect known identifiers with marketing data like age, gender, and household income using third parties like Faraday.
- You de-duplicate and "master" records: e.g. by saying that two different emails belong to the same person
- You upload unknown identifiers to ad networks and they resolve them into users on their platforms.
Finally, it's important to know the terms first- and third-party data. First-party data is data that you collect and own, and can include both known and anonymous identifiers. It also includes transaction amounts, order details, product details, etc. Third-party data, on the other hand, is data that is owned by others, but is available for specific uses. (You may also hear about “zero-party data,” which is a special kind of first-party data that users explicitly provide, such as by filling out surveys.)
When you unify first and third party data, you can get age, gender, household income, and other traits for a user so that you know both what they bought (first-party data) and who they are (third-party data). You’ll generally get the highest enrichment or match rate by starting with known identity, but it's possible to start with anonymous identity, too.
Why does identity resolution matter?
If your business has more than just one useful database of information (which is highly likely), identity resolution is mandatory in order to properly understand not only who’s who within your data, but also how they’re engaging with your business. Doing so opens up a world of use cases that can be done efficiently because you’re able to group similar customers and leads together: personalize their journeys, recommend first-and-next best offer, plan retention campaigns, and more.
For example, transaction data stored in back office systems can be combined with behavior observations in the marketing or product teams, with call logs from customer-facing teams, and so on. To illustrate this latter point, customer churn prediction is often much stronger when it takes into account activity like messaging or calling.
Taking this a step further–when generative AI is available–identity resolution can help take unstructured data from call center transcriptions and combine it with structured data like transaction histories. This allows you to use sentiment analysis or entity extraction to create data attributes (i.e. predictive features) that can be combined with other first and third party features in predictive models, such as lead scoring.
Why identity resolution is difficult to implement
Identity resolution is important, but it's hard to implement. To start, the datasets involved need to have PII that can be compared. For example, maybe you have transactions with billing addresses included in one dataset, and views/clicks by email address in another. To resolve the identities in these two datasets, you’d need to purchase third-party email hashes connected to postal addresses so that both have billing address and email data, then you’d need to ensure the data is standardized so that they can be compared.
The process is further complicated when you consider that people aren’t static–they move addresses, they have kids, their habits change–life goes on. You'll need to rent or purchase historical address data to make your graph complete. Your customers and leads change, and your data should be able to change with them.
What does the identity resolution market look like?
There are a wide variety of identity resolution products on the market. Some are pre-integrated into the systems that use them, such as traditional "packaged" CDPs, purpose-built person-level AI infrastructure like Faraday, and others. These identity resolution systems primarily serve the purpose of the software they're integrated with, and offer the fastest time-to-value. Software in the master data management space like Reltio is dedicated to resolving and de-duping records for use by downstream systems.
There are also data warehouse-native identity resolution packages, such as Hightouch Identity Resolution or AWS Entity Resolution that run directly inside of a customer's cloud account or data warehouse. These provide standard functions for resolving identity that can be applied to any business, though they won't be immediately usable out of the box. TransUnion and other traditional data aggregators offer identity resolution packages on the Snowflake Marketplace that serve to connect first-party data to third-party identifiers and data. Finally, consultants like Deloitte will often build custom identity resolution projects on a per-client basis, if that client has previously purchased third-party data.
Due to competitive pressure from all of the data warehouse-native and standalone identity resolution providers, some software with built-in identity resolution like Faraday now allow data warehouse-native identity resolution too, which can be a good option that combines the low time-to-value with a flexible, proven base for other software and processes to be developed on top of.
How Faraday’s identity resolution works
Faraday’s advanced identity resolution is built in, which means you don’t need to separately license any data or go through the laborious process of manually unifying it with your own to create distinct profiles of your customers and leads. All parts are included: from data and data unification that’s continuously up-to-date and responsibly sourced, to identity resolution and AI-powered customer predictions. Whether you’re interested in prioritizing your best leads and rejecting leads that won’t end up converting, seeing which customers are going to churn or finding their next best offer, Faraday has you covered from end to end.
To start, Faraday securely ingests your data through a connection to wherever your data is stored (or via CSV file), after which you describe your data to Faraday via datasets. In your datasets, you’ll tell Faraday what personally identifying information (PII) fields to look for (column mapping), as well as what events take place in your data, which you’ll use to define your customer prediction objectives. Everything Faraday does is fully API-enabled, too.
With your data defined, we search the Faraday Identity Graph (FIG) for matching PII through fields like email, first_name, and address. Once a match is found, all data that you have on this individual is unified with and enriched by their data in FIG. From demographics, to financials, property data, and more, 1,400+ robust traits supplement your data on how they interact with your business with how they exist outside of those interactions.
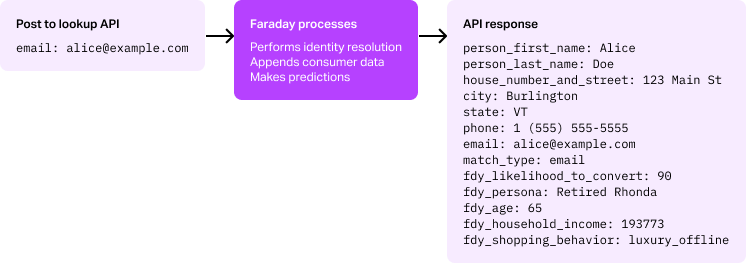
The result is a unified, enriched customer profile that’s embedded directly into your applications and workflows–with customer predictions on top–for all of your customers and leads, ensuring that your teams have all of the information they need to engage effectively.
At the end of the day, identity resolution is critical to unlocking truly data-driven marketing and AI/ML projects. With it, all of your data comes together from its disparate sources to form unique identities for each individual. These identifiers cover their engagement with your business through visits, email addresses, transactions, etc, their marketing highlights like age and income, and any other traits that you have. With identity resolution, you can effectively predict which leads are most likely to convert and which you shouldn’t waste time and money on, which customers are most likely to churn, their buyer persona, what product or service to recommend next, and more.
Faraday handles the ML struggle so that you can focus on your downstream applications and workflows.
Andy Rossmeissl
Andy Rossmeissl is Faraday’s CEO and leads the product team in building the world’s leading context platform. An expert in the application of data analysis and machine learning to difficult business challenges, Andy has been running technology startups for almost 20 years. He attended Middlebury College and lives with his wife in Vermont where he lifts weights, makes music, and plays Magic: the Gathering.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.