How SalesRabbit uses Faraday to enhance their field sales app with data & AI
Launched as “DataGrid AI,” SalesRabbit’s predictive lead scoring tool guides canvassing teams to best-fit territories, helps with route planning, and leaves reps with clear guidance on which households to prioritize when in the field.


See our complete guide: Powered by Faraday — embedding predictive AI in your platform.

Making a powerful tool even smarter
SalesRabbit is the leader in software for field sales teams. Their DataGrid solution supplies canvassers with household data on specific properties and homeowners in their territories, providing essential context as they knock on doors. However, the SalesRabbit product team recognized that static data points on each property provided limited context for sales reps.
They realized that, if they could identify which attributes of a homeowner or property could predict the likelihood that a prospect would become a customer, then they could use that information to inform how their sales reps approached their day-to-day responsibilities. For example, solar clients would not only know which houses had the right amount of sun exposure for solar panels, but also which of them most closely fit the model of historical solar adopters. Pest control clients would not only know what material houses were made out of, they could also know if the homeowner would be more or less likely to say yes to regularly scheduled inspections or not, and so on.
Furthermore, if they had a way to predict which neighborhoods had the highest concentration of likely customers, then DataGrid could direct sales reps' efforts more efficiently.
The challenges of building predictive AI models from scratch
SalesRabbit identified three main obstacles to them building effective predictive AI models in-house:
- A lack of data about consumers.
- The long ramp time to build effective predictive models.
- Resources to test models for accuracy and continue to provide transparency about the models efficacy.
Licensing more customer data
Predictive models need a deep well of data to find an accurate signal. Despite the wealth of data SalesRabbit had on homeowners, adding an ML layer to DataGrid would require thousands more data points to ensure accurate models. Psychographic data, shopping behaviors, demographic data, financial information, and more would all need to be vetted, licensed, and reconciled with their existing data before predictions could be made.
Extensive time and resources dedicated to prediction
To build a customer prediction pipeline in-house, the SalesRabbit team would also need to grow their existing data science team. They couldn't just reorganize other team members for a temporary sprint. Not only is the typical timeline for an ML program multiple years, they’d need to invest to continuously maintain those models over time.
Limited transparency and scalability of cost
For the C-level team at SalesRabbit, it was critical for the solution to their challenge to be scalable. The original timeline for building this feature entirely in-house was multiple years and required a major investment from their data science team to get started.
Additionally, SalesRabbit's customer base includes both enterprise home service companies and small, regional installers. Creating a customer prediction pipeline comes with a tremendous computing cost, and running hundreds of millions of scenarios to build a model that works quickly can grow that cost exponentially–and unpredictably. How do you forecast the budget for the computing cost when the number of predictions made monthly for large and small organizations varies dramatically from month to month?
The partnership

Realizing that an in-house build carried these risks, the SalesRabbit team shopped for existing best-in-class infrastructure that they could build on.
Faraday was the perfect fit for the team to implement customer predictions quickly, and at scale.
Built-in consumer data for predicting customer behavior
Faraday has over 1,400+ attributes built into its platform, which mean all of this data was available on day one. Even better, it could be seamlessly combined with their existing data sets–no identity resolution required.
Employing this font of data on nearly every U.S. adult, SalesRabbit had everything they needed to understand the patterns and trends of their customers' ideal homeowners, regardless of which vertical their customers work in.
Preserving existing data science resources and cutting product build time with Faraday recipes
Faraday’s plug-and-play customer behavior predictions meant there was no need to pull their data scientists off of other projects to build a customer prediction pipeline from scratch. SalesRabbit used pre-built prediction recipes as an accelerator to test and refine models before incorporating them into their product. This allowed them to shrink a multi-year roadmap to a matter of days, and free up their data science team to focus on other efforts.
Peace of mind with transparency and scalability of cost
To the product team at SalesRabbit, building a customer prediction pipeline from scratch came with no small level of forecasting uncertainty. How much should they invest to launch? How much will it cost to scale up as their customer base grows?
With Faraday, they found pricing certainty, which allowed SalesRabbit to know exactly what to expect as they scale up.
The results
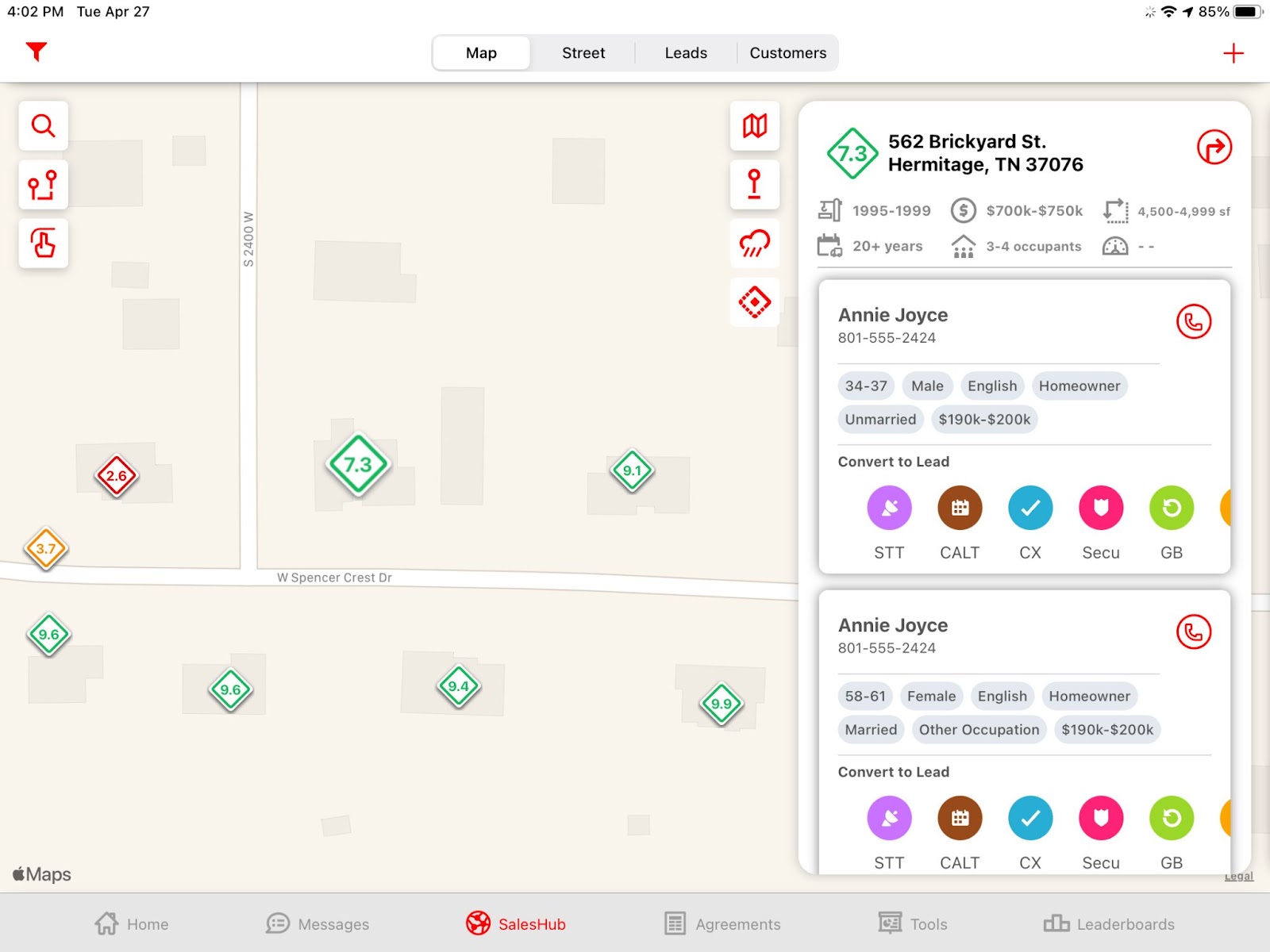
To SalesRabbit, choosing to embed customer predictions into their software rather than build it in-house was a game-changer. Once SalesRabbit connected their data and created their initial predictive models, Faraday’s developer API made it easy to start embedding Faraday’s predictive features into DataGrid, and in a fraction of their original timeline.
Launched as “DataGrid AI,” SalesRabbit’s predictive lead scoring tool guides canvassing teams to best-fit territories, helps with route planning, and leaves reps with clear guidance on which households to prioritize when in the field. And because all of Faraday’s predictions are cached in advance, overall app performance improved once they were integrated.
Andy Rossmeissl
Andy Rossmeissl is Faraday’s CEO and leads the product team in building the world’s leading context platform. An expert in the application of data analysis and machine learning to difficult business challenges, Andy has been running technology startups for almost 20 years. He attended Middlebury College and lives with his wife in Vermont where he lifts weights, makes music, and plays Magic: the Gathering.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.