All blog posts
Product
How predictive lead scoring works — and why it outperforms traditional methods
Using lead scoring, American Standard went from a 5.56% contact rate to 20% — and high-score leads converted at 3x the rate of others. This is a practical guide to how predictive lead scoring works and how B2C teams use it to optimize their entire sales motion.



Robin Spencer &
Ben Rose
on
American Standard's contact center was making 20,000 dials a day and reaching almost no one — a contact rate of 5.56%. After layering in predictive lead scoring, that number climbed to 20%, and high-score leads converted at 3x the rate of others. Nothing about their leads changed. What changed was the context powering how they prioritized them.
Predictive lead scoring uses machine learning to rank your leads by their likelihood to convert — so your team knows who to call, when to reach out, and how to engage before a single conversation starts. It's the single highest-leverage place most B2C teams can add customer context to their sales motion. This guide covers how it works, how the best teams use it, and what it takes to build a system that moves the needle.
What is lead scoring?
Lead scoring ranks leads by their likelihood to convert so sales and marketing teams can focus on the right ones. But not all lead scoring is created equal — there are two fundamentally different ways to do it, and the choice shapes everything downstream.
Traditional lead scoring models often rely on a point-based system where humans determine the lead scoring criteria—typically a combination of basic demographic information and online behaviors such as pageviews, email engagement, or form submissions—and assign points to leads when they meet it.
While these point-based lead scoring models can help marketing and sales teams prioritize their efforts, they come with significant drawbacks. Lead scoring criteria are often arbitrarily decided, resulting in lead scores that may not accurately reflect a lead's true potential. Additionally, because they rely heavily on first-party engagement data, lead scores often end up being a lagging indicator of a lead's conversion likelihood.
Predictive lead scoring uses machine learning trained on your actual conversion outcomes. The model learns which combinations of attributes — first-party behavior plus third-party consumer context — predict that a lead will convert. With the right dataset, it can score a lead's likelihood to buy before they ever visit your site or open an email.
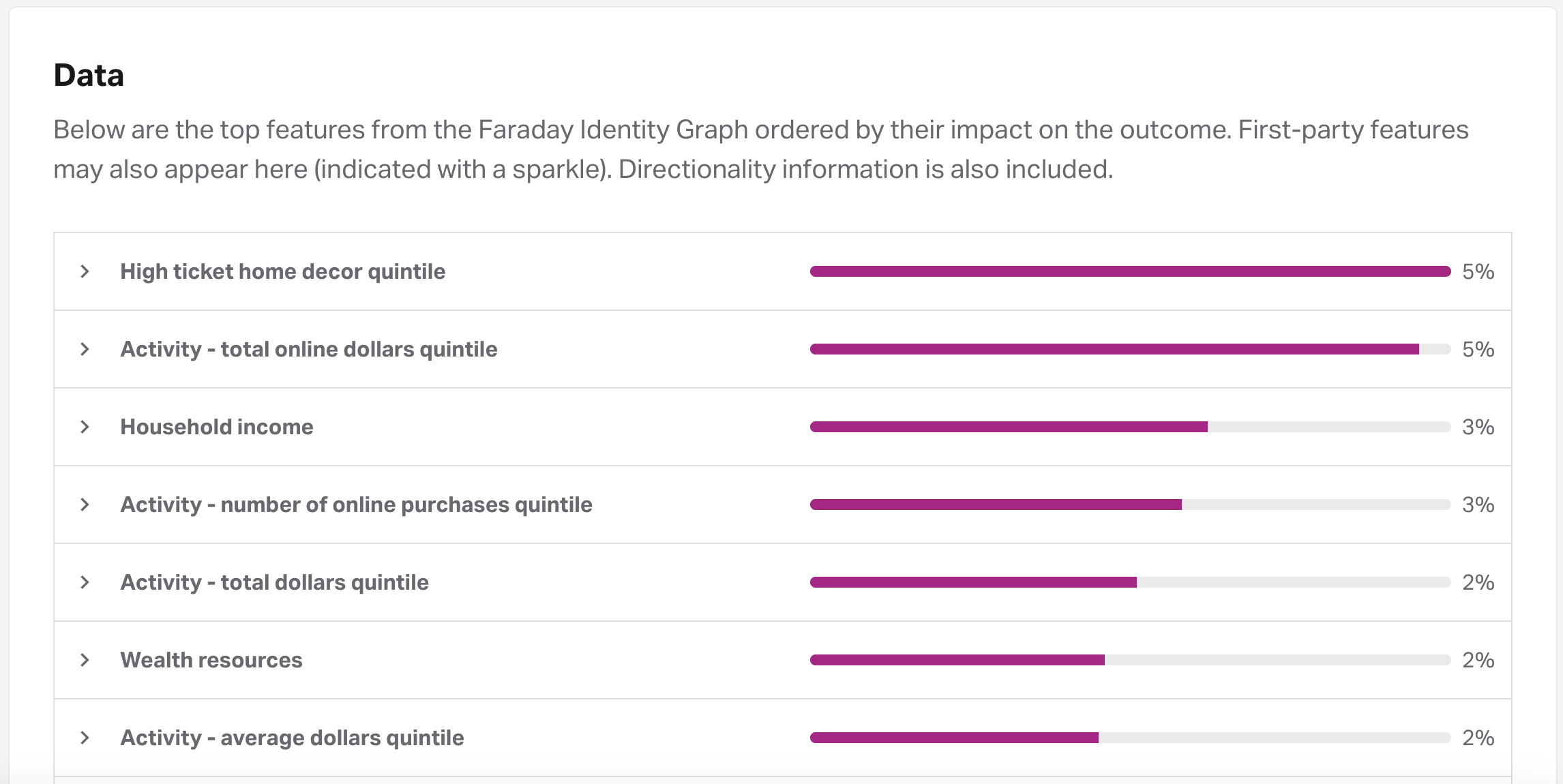
Note: the image above illustrates important features surfaced in Faraday model reports.
| Feature | Traditional lead scoring | Predictive lead scoring |
|---|---|---|
| Method | Rule-based (manual point systems) | Machine learning trained on past outcomes |
| Data used | Basic demographics, behaviors, form fills | Hundreds of behavioral, demographic, and contextual signals |
| Scalability | Manual tuning required per campaign | Fully automated, adaptable, and always learning |
| Accuracy | Assumptions-based, subjective | Outcome-driven, empirically validated |
| Maintenance | Static, often neglected | Continuously improved via retraining |
| Transparency | Clear but simplistic | Advanced but explainable (e.g., model reports) |
Predictive lead scoring is one application of a broader practice called propensity modeling — predicting any future customer behavior, not just conversion. The same techniques power churn prediction, LTV modeling, and next-best-offer recommendations.
What you need for great B2C predictive lead scoring
The best predictive lead scoring doesn't rely on a single source of data. It combines two things: the real-world context of who your leads actually are — their financial situation, lifestyle, and household — and the actual engagements they've had with your brand. You bring one half. Faraday brings the other.
What you bring
- Your lead records (identity data) — names, addresses, phone numbers, and emails — the starting point for connecting your data to real-world consumer profiles.
- Your conversion history (transactional data) — who became a customer, when they converted, and what they paid — defines the cohorts the model learns from: customers, leads, stale leads. Without clearly labeled outcomes, the model has nothing to learn from.
- Your engagement history (engagement data) — pageviews, email subscriptions, free trial signups — captures how your leads have interacted with your brand and how those behaviors relate to conversion.
What Faraday brings
Before any modeling happens, Faraday completes your identity data — filling in the gaps in your CRM records with missing addresses, phone numbers, and emails. This alone maximizes your match rates and expands your addressable audience.
But that's only where it starts. Once your records are complete, we combine your first-party data with our third-party consumer records — 1,400+ data points across demographic, financial, property, and lifestyle dimensions, drawn from the Faraday Identity Graph (FIG) covering 240M U.S. adults — to build models trained on your real customers and outcomes.
The result is custom predictive data: bespoke data points generated specifically for your business. Lead scores are one example. Others include next-best-offer predictions, churn likelihood, and lifetime value estimates.
How B2C teams use predictive lead scoring
Predictive lead scoring is an optimizer for your sales motion at every stage — giving reps the context to know how, when, and where to engage every lead. Scores deploy in real time into your CRM, ad platforms, and routing tools, so the intelligence shows up where your team already works. Suppression and rejection are part of the toolkit, but they're the floor, not the ceiling.
Here's where the highest-leverage use cases sit, in order:
-
Lead prioritization: This is the use case that produces the biggest gains. Predictive scores let you tier your leads and route the strongest ones to your best reps, with the most aggressive follow-up cadence. Mid-tier leads move into the right workflow. Lower-fit records shift into nurture instead of taking up agent time. American Standard worked with Faraday and outboundIQ to do exactly this — moving lead scoring from a top-of-funnel blocker to a full-funnel routing optimizer. Their contact rate jumped from 5.56% to 20%, and high-score leads converted at 3x the rate of others. Momentum Solar took the same approach and improved call center conversions by 33%. These patterns play out across consumer verticals, but they're especially powerful in home services and other industries where contact center economics make every dial count.
-
Product recommendations: If your predictive system supports product-specific modeling, you can predict which products or services a lead is most likely to purchase. Reps and marketing systems use those scores to make informed recommendations across every touchpoint.
-
Custom incentives and discounts: Instead of blanket promotions, predict the likelihood of leads converting to high-LTV customers and offer targeted incentives only where they'll move the needle. This protects margin on customers who would have bought anyway and concentrates spend where it matters.
-
Lead suppression: Rank your leads, set a suppression threshold, and stop spending on the bottom tier — whether that's direct mail, paid follow-up, or sales effort. Useful, but a much smaller lever than prioritization.
-
Lead rejection: If you buy leads from generators or aggregators, you can use predictive scoring to reject leads below a minimum conversion probability before they ever hit your CRM. Saves money, but it's the narrowest application of the technology.
Reject and suppress when it makes sense. Prioritize everywhere else.
Why Faraday
Most data vendors give you a snapshot of who someone appears to be today. FIG includes longitudinal data spanning years of each individual's history. A lead who looks identical in a snapshot today may have a very different trajectory, and trajectory is what actually predicts conversion. That's what sets Faraday apart.
It's also production-ready out of the box. The data is normalized to meet modern data science requirements, so there are no expensive licensing negotiations and no raw data to clean and restructure before you can use it.
The data is also responsibly sourced — no third-party cookies, no social scraping.
Faraday vs. CRM-native scoring
Your CRM only knows what's in your CRM. Klaviyo, HubSpot, and other platforms with built-in predictive scoring are limited to your first-party data — how leads have behaved in your system — because that's all they can see.
Faraday trains on the combination of your first-party data and 1,400+ FIG consumer attributes, identifying patterns about who your leads actually are in the real world: their financial situation, lifestyle, household, and trajectory over time. That's the difference between scoring based on what someone did on your website and scoring based on who they actually are.
Ready to put context behind every lead?
If you're a B2C team that wants to see predictive lead scoring in your own data, there are two ways to start:
- Self-serve: Get started on buy.faraday.ai — upload your records and get scored leads flowing into your stack in minutes.
- Enterprise: Talk to a Context Consultant — we'll walk through your funnel, your data, and what's possible.
FAQ
Isn't predictive AI just a black box?
Not at Faraday. Every model includes explainability breakouts that document the data used, what the model was trained to predict, and how well it performed. Feature importance scores show which attributes are driving conversion likelihood, and segment insights break down what's working in human-readable terms. For a deeper technical dive, see Seamus Abshere's post on why first-party data and RFM isn't enough.
What if I don't have enough first-party data?
Most brands have more than they think. And when first-party data is genuinely sparse, FIG fills in the gaps with verified third-party context. Models can learn from behavioral and contextual signals well beyond what's in your CRM. Predictive lead scoring doesn't require perfection — it needs patterns.
What are the biggest challenges of running predictive lead scoring well?
Two things. First, data quality: the accuracy of your predictions depends on the completeness and consistency of the data you feed the model — particularly identity data, which determines how well your records match against third-party consumer profiles. Second, retraining: customer behavior shifts over time, and models need to be refreshed regularly to stay accurate. A good platform handles both of these for you.
How long does it take to get predictive lead scoring up and running?
For most B2C teams using Faraday, a working predictive lead scoring model can be deployed within days, not months. The longer pole is usually data preparation on the client side — getting clean, well-labeled historical lead and customer data into a usable format. Once that's in place, model building, validation, and deployment happen quickly.
Robin Spencer
Robin Spencer is Faraday’s COO, leading all of our client-facing teams—from sales to customer success. Her mission is simple: help consumer businesses uncover where data can meaningfully improve (and profitably accelerate) the customer journey. Robin brings experience from Accenture, Google, and Clearbit (acquired by HubSpot), where she focused on using data to drive real, measurable business outcomes. When she’s not geeking out about data and operational strategy, you’ll find her tending her cut-flower garden, knee-deep in a creative project, or wandering in the woods nearby.
Ben Rose
Ben Rose is a Growth Marketing Manager at Faraday, where he focuses on turning the company’s work with data and consumer behavior into clear stories and the systems that support them at scale. With a diverse background ranging from Theatrical and Architectural design to Art Direction, Ben brings a unique "design-thinking" approach to growth marketing. When he isn’t optimizing workflows or writing content, he’s likely composing electronic music or hiking in the back country.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.