All blog posts
Product
How Faraday helps mitigate harmful bias in machine learning
Mitigating harmful bias with Faraday is simple, whether through our developer API or in-app. Learn more about how Faraday mitigates bias in your customer predictions.



Thibault Dody &
Andy Rossmeissl
on
This article is a followup to our bias reporting article, and aims to provide a high-level overview of how Faraday users can mitigate harmful bias.
What is bias mitigation in machine learning?
Bias mitigation in machine learning encompasses a set of methodologies and techniques devised to diminish and ideally eradicate unjust and discriminatory predictions inherent in the decision-making processes of artificial intelligence (AI) systems. This is a key component of Responsible AI.
Bias, often unintentional, may infiltrate these systems as a result of the historical data they are shown, leading to inequitable treatment of specific demographic groups. For example, there is a history of discrimination against specific minority groups in financial lending, and this history can perpetuate bias if it is not intentionally mitigated.
It is important to note that not all algorithmic bias is harmful. Predictions about, for example, the likelihood of buying products that are exclusively relevant to, say, certain age groups will and should discriminate in favor of those age groups. For the remainder of this article, when we discuss bias, we’re excluding innocuous bias like this and focusing on harmful bias.
Bias mitigation ensures that AI systems render decisions characterized by impartiality and fairness, irrespective of variables such as race, gender, or other sensitive attributes. This undertaking is pivotal in the development of AI systems that uphold principles of fairness and equality for all individuals.
The subsequent sections of this article describe how Faraday’s bias mitigation feature allows users to create fair propensity predictions. For more on bias management in Faraday, read our bias management announcement.
How to reduce harmful bias in machine learning
When predicting propensity, Faraday can mitigate bias in two broad ways:
- The first step is to ensure that the predictive algorithm considers every demographic group as equal. In order to do so, Faraday rebalances your historical data before submitting it to the algorithm for pattern discovery.
- Second, when later making predictions, Faraday will adjust the nominal propensity ranking to ensure that the highest scorers for each demographic are ranked highly overall. This ensures that the predictions are meeting the fairness objective while maximizing predictive lift.
Some Faraday terminology will be used here, and will link to documentation.
Unbiasing historical data
In order to mitigate bias in a client’s existing customer data, Faraday assigns different “weights” to each customer in the data to fine-tune their influence on the model's learning process. The goal is to address and rectify biases present in the data, ensuring that the model gives equal consideration to all relevant examples.
To understand this process, consider an example: a home mortgage company. Given historical disparities arising from discriminatory laws and government policies (among other reasons), some demographics are less likely to appear in the company’s customer data.
Formally, Faraday will discover this by noticing a difference between the “attainment” (all customers) and “eligible” (regional adult population) cohorts in one or more dimensions of concern. For example, we could find fewer women than men in the historical customer data, even though the regional population is an even split: a disparity that has no rational basis. Without correction, the algorithm would believe (incorrectly) that there is some intrinsic quality which makes men more likely mortgage customers than women.
To unbias the historical data, Faraday would give higher weights to customers in underrepresented or disadvantaged groups, increasing their influence on the algorithm while it is looking for salient patterns. Building on the mortgage example above, Faraday could give higher weight to the proportionally fewer women customers, evening out their influence versus men. This results in more equitable predictions for individuals belonging to these groups.
By adjusting the weights assigned to different customers, Faraday aims to create a more balanced and fair learning process, ultimately leading to AI models that provide fairer outcomes across diverse demographic groups.
Unbiasing predictions
When you include a propensity outcome in your pipeline, Faraday can take additional measures to rectify potential biases in the resulting predictions. After the initial predictions are made, this approach evaluates and adjusts them to ensure fairness and reduce discriminatory outcomes.
Given that the first step eliminates bias in the historical customer data, why is this second step even necessary? When we unbias historical data, we can't alter the algorithm to completely ignore the overrepresented population in favor of the underrepresented one–we’re simply telling it to pay more attention to the latter until it has a roughly equal representation. This weighting can have a cascading effect that creates biases of its own, though.
To take the mortgage example even further, maybe the women customers tend to be older than the non-customers, whereas the men customers tend to be younger than their non-customer counterparts–after the weight adjustment, this can make the trait age mean that an individual is more likely to attain the outcome if they are older, unfairly penalizing those without that characteristic, which is why this step is crucial.
In this step, Faraday looks for differences between the demographic makeup of the pipeline’s eligible population and the subgroup receiving the highest scores. The predictions are then adjusted to align more closely with the desired fairness objectives.
This method allows for the correction of biases that may have been present in the original predictions, promoting a more fair distribution of outcomes across different demographic groups. By incorporating fairness considerations after the initial predictions are generated, prediction this re-ranking contributes to developing machine learning models that exhibit improved fairness and reduced problematic disparity in their decision-making processes.
Mitigating harmful bias with Faraday
As of the publication of this article (February 2024), Faraday currently allows for bias detection and mitigation for the age and gender dimensions (these features are often referred to as protected classes or Dimensions Of Concern).
When you define a propensity outcome in Faraday, you can choose how you want the system to handle bias:
-
No mitigation: The outcome fairness is only reported as part of the outcome dashboard. No further transformation is applied to ensure that protected classes are treated fairly. This is perfectly appropriate in cases where the product or service being sold is intrinsically linked to certain demographic groups.
-
Equality: This mitigation strategy ensures that demographic patterns are similar between the eligible population and the target group (those with the highest scores). For example if “young adult, women” represent 25% of your eligible population, we ensure that any population targeted from the pipeline will contain 25% of “young adult, women”.
The chart below depicts the effects of historical data bias mitigation using the “equality” setting with three populations (A, B, C). Population A is underrepresented in the customer data (attainment population)—30% are customers vs. 47% in the overall population while B and C are both overrepresented. The mitigation process ensures that in the target group, population A accounts for 47% while B and C account for their original 14% and 39% respectively.
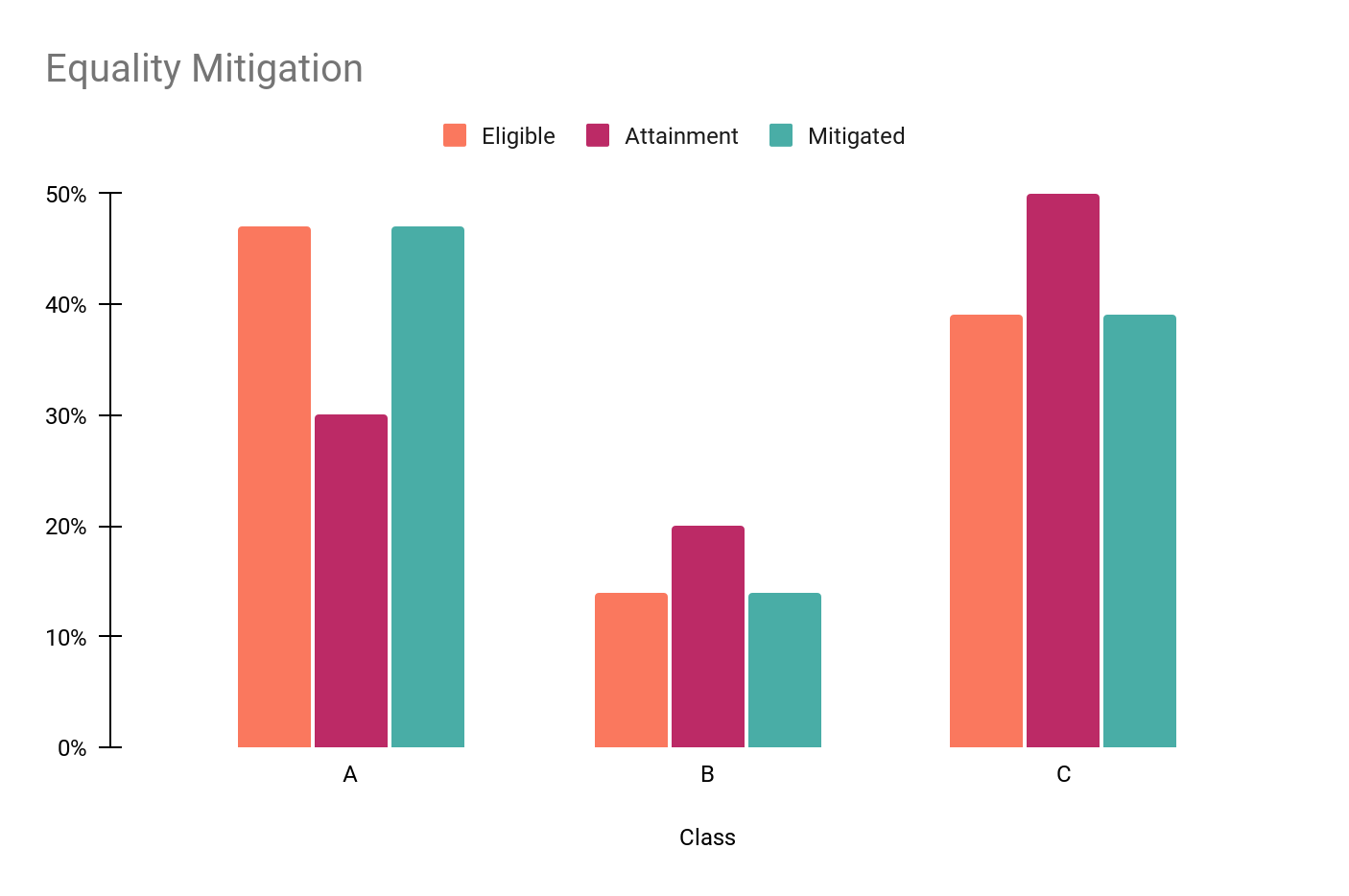
-
Equity: This mitigation strategy “inverts” bias so that populations that were historically underrepresented are now instead prioritized.
In the example below, the customer group (attainment cohort) consists of 30% of population A, 20% of population B, and 50% of population C. The equity mitigation is going to promote the underrepresented populations A and B at the expense of population C. The target population will contain 37% of A, 47% of B, and 16% of C.
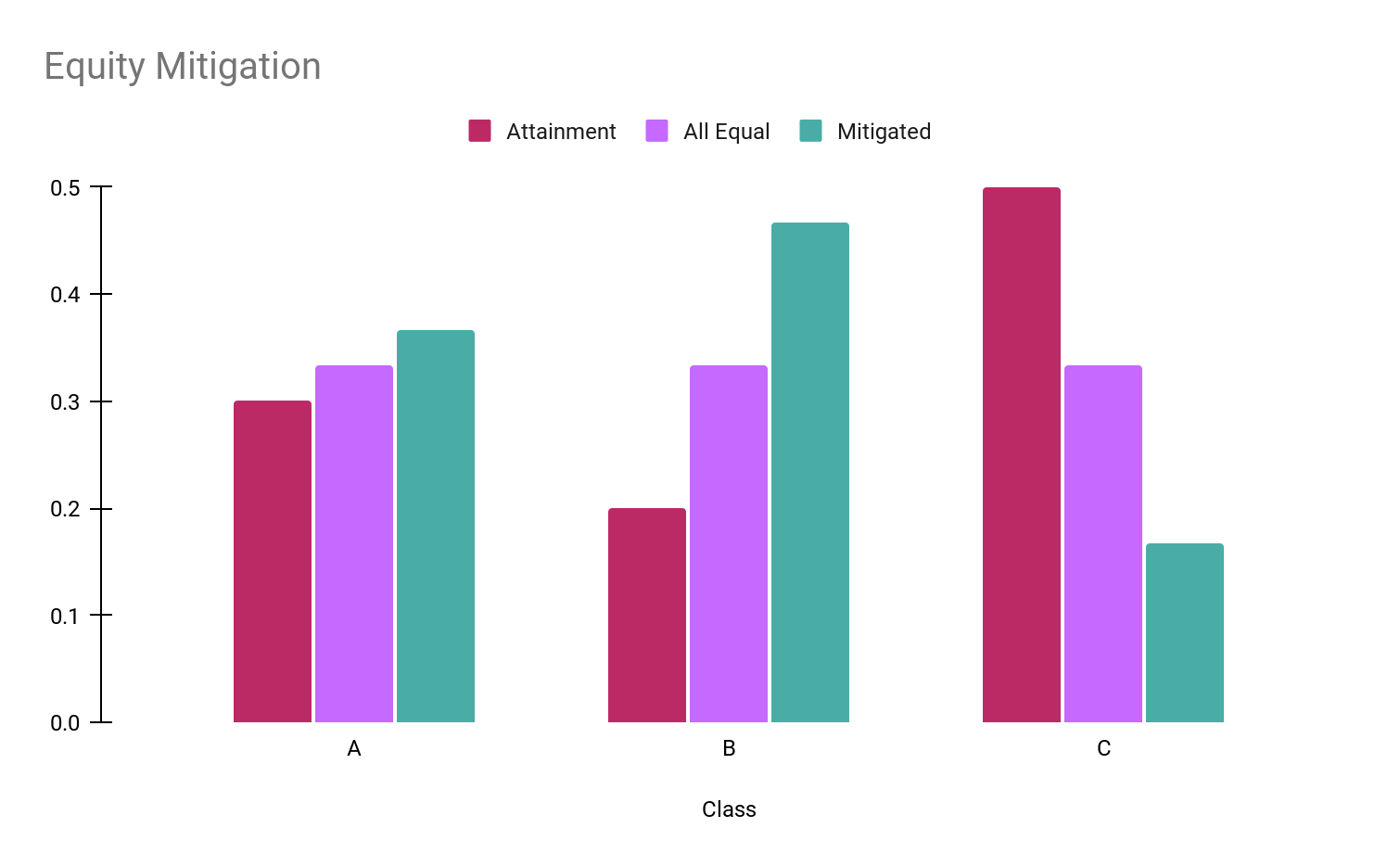
Note that when mitigating bias, Faraday will consider all dimensions simultaneously, leading the system to consider subpopulations like “young adult, women” and “middle-aged men.”
Does mitigating bias hurt performance?
Because the bias mitigation process necessarily alters the ranking and promotes sub-populations with otherwise lower predicted scores, it can reduce lift.
That said, the impact is often small. The top two graphs below depict the impact of equality mitigation on Gender. The lift curve for the un-mitigated model is only slightly better than the one for the mitigated model. The main difference lies in the 20% to 40% score percentile range with lift in that range decreasing from ~300% to ~220%.
The two bottom graphs show the mitigation at work. On the left, the un-mitigated model will create a target group with 2x too many males.
After mitigation, the graph on the right shows only a slight discrepancy between the fair proportion of each gender, within 3%. This is a significant fairness improvement over the initial target population breakdown with only a minor reduction in performance.
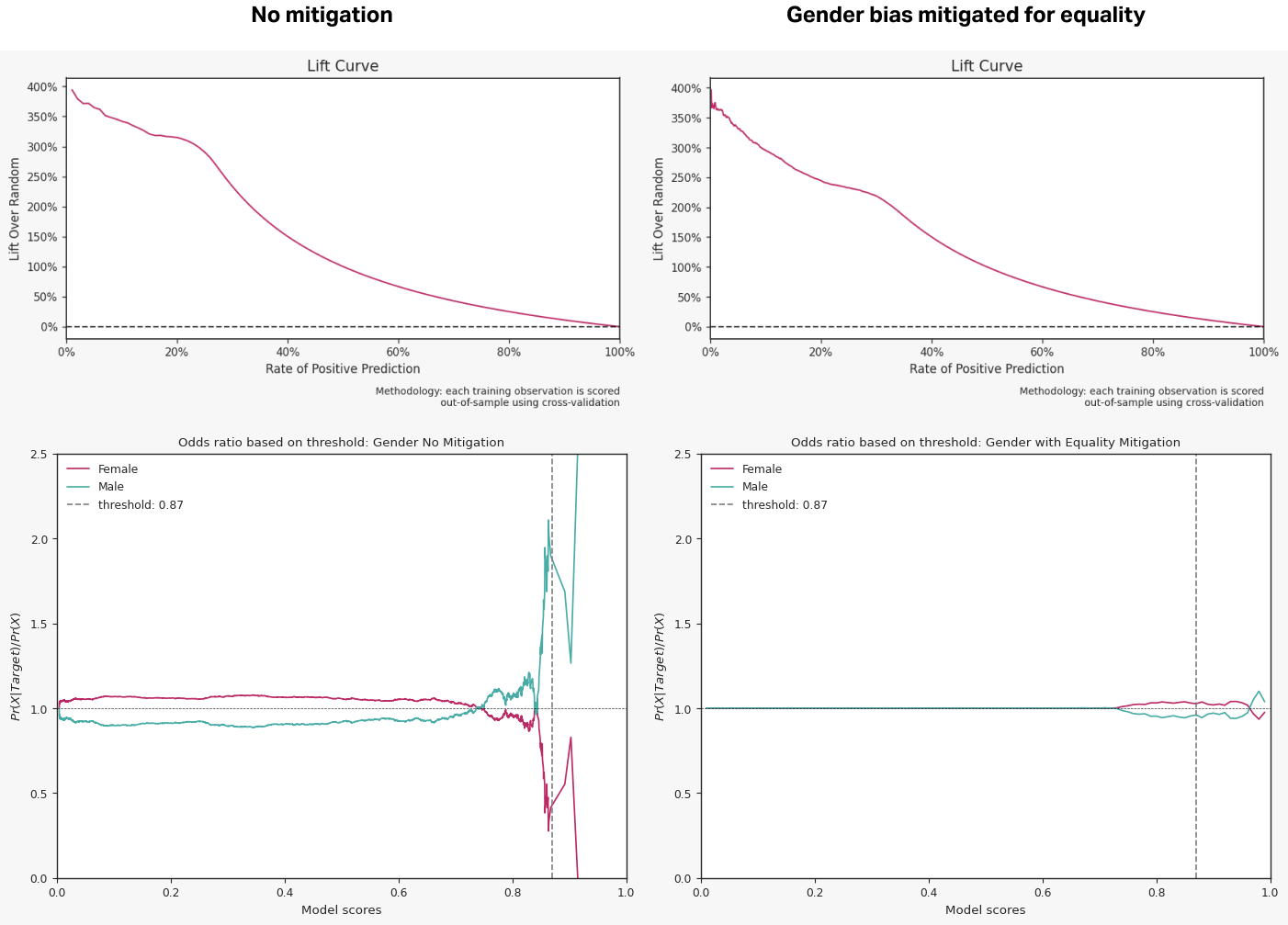
Why mitigate bias?
Bias isn’t inherently harmful. Earlier in this article, we touched on innocuous bias that occurs when products or services are explicitly designed for and marketed toward certain groups, like a womens’ swimwear brand marketing mostly to women. It’s the other, harmful–and often hidden–bias that should be surfaced and mitigated.
With Faraday, bias mitigation is easy. If you find that a predictive outcome you created has bias that you want to mitigate, simply create a new outcome using the same cohorts of people, toggle mitigation on for the sensitive dimension in question, select your mitigation strategy, and save the outcome. Once it finishes building, compare the bias report from the un-mitigated outcome with the report from the mitigated outcome. Alternatively, use the bias_mitigation object with the API call to create an outcome.
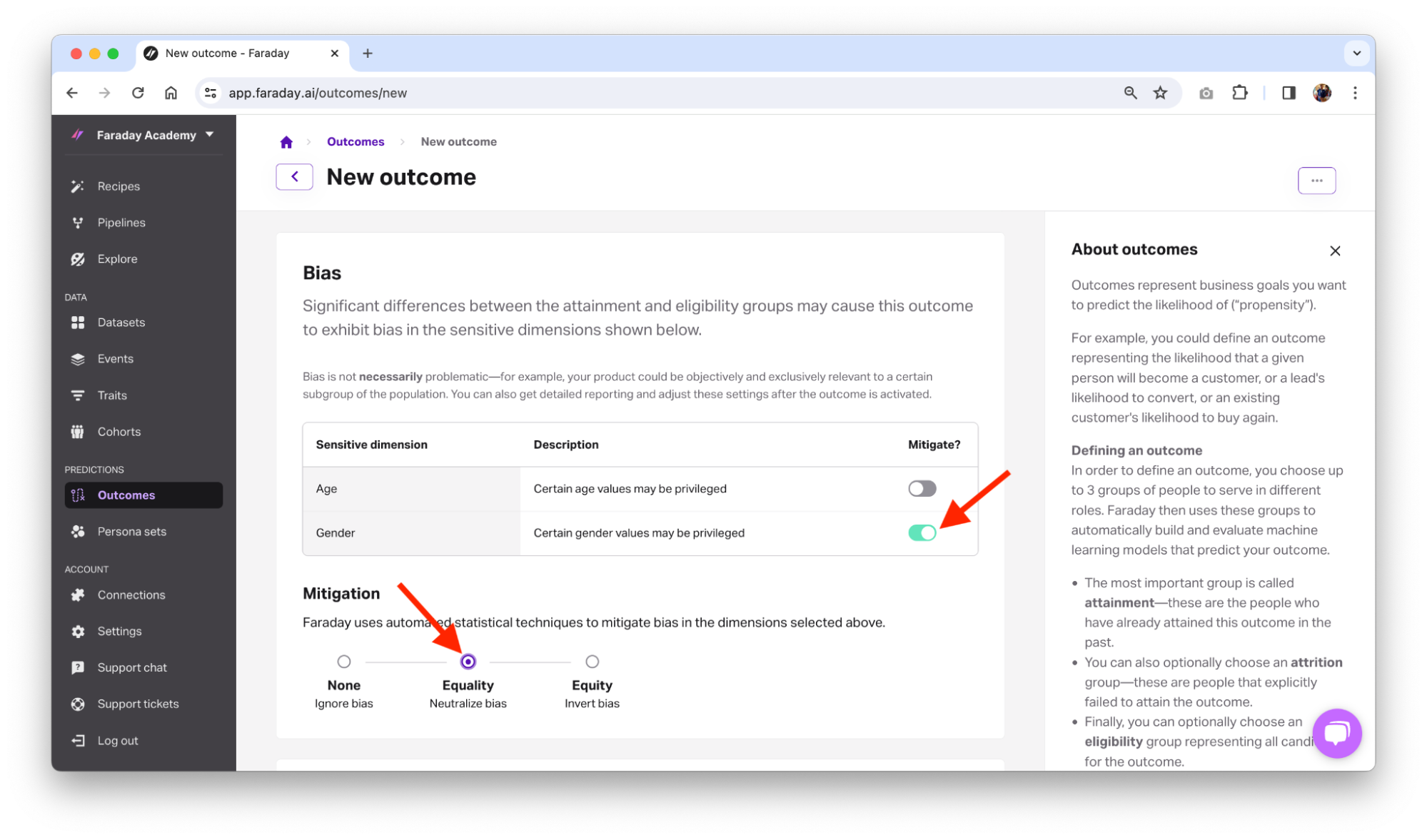
It’s in the best interest of anyone developing or using AI to do so responsibly. Whether you’re using generative AI for email copy and creative, predicting customer behavior like we walked through in this article, or something else entirely, you should be wary of the existence of bias in the data that the algorithms are using, and how it impacts who you market and sell to. By employing responsible, explainable AI, you can build a foundation of trust between not only yourself and your customers, but between your business and your data.
Responsible AI isn't just good business–it’s the right thing to do.
Thibault Dody
Thibault is a Senior Data Scientist at Faraday, where he builds models that predict customer behaviors. He splits his time between R&D work that improves Faraday's core modeling capabilities and client-facing deployments that turn those capabilities into real results. When not deploying ML pipelines, he's either road cycling through Vermont or in the shop turning lumber into furniture, because some predictions are best made with a table saw.
Andy Rossmeissl
Andy Rossmeissl is Faraday’s CEO and leads the product team in building the world’s leading context platform. An expert in the application of data analysis and machine learning to difficult business challenges, Andy has been running technology startups for almost 20 years. He attended Middlebury College and lives with his wife in Vermont where he lifts weights, makes music, and plays Magic: the Gathering.

Ready for easy AI?
Skip the ML struggle and focus on your downstream application. We have built-in demographic data so you can get started with just your PII.