Connections
Connections are how you connect your data with Faraday, whether it's in a database, warehouse, cloud bucket, or somewhere else entirely.
Connections overview
Connections are how you connect your data with Faraday. By default, you can create a Faraday connection to your database, data warehouse, or cloud bucket. For an additional cost, a connection can also be made to your CRM, ESP, or some other software via Faraday-managed connection.
Connections can serve as both the beginning and end of your data's journey in Faraday. When a connection is created, your data–wherever your connection is–can be used to create datasets, where you'll define event streams and traits that are then used to build cohorts. From then, you'll create your predictions: outcomes, personas, and recommenders. Last, you'll create pipelines to deploy predictions back to a connection you've made, or to CSV.
For connection creation instructions using both the Dashboard UI and API, see our how-to docs for connections.
👍Key takeaway: connections
Connections are how you connect your first-party data with Faraday. You'll use them to pull your data into Faraday, then create datasets to describe your data. On the other end, you can use connections to push your customer predictions back to your stack.
Faraday-managed connections
Faraday-managed connections can be created at an additional cost to either to pull data from or deploy predictions to other, non-database software within your stack, such as an ESP, CRM, or ad platform. To create a Faraday-managed connection, use the appropriate section while creating a new connection in Dashboard, or using the API via the option parameter in the createconnection API request.
Once you create the connection, please create a support ticket so that a Faraday support team member can initiate the connection on Faraday's side.
Faraday's public key
If you are encrypting your files before sending to Faraday, please use this public key:
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGNBGGyYtABDADE2qEsdPM7s3uLlMYbObnUTMh+4EX76WrNsxboNtJPFlZPNHwi
aO9xA2vaffcuSsYsy+UxbWWCrzIU3CF3IZ2Yjw1w5JWhqNfTboOLuILb2p0+HoW9
8pZpdkav5BFm0s+Ym99WYh0HUlZ5NVcaTWTHHarwO/w/5sh9h6ieTZviAinFKt4c
I7VcBCJOGDbI44CG8rXW0NKxsZrVejemt/UtV55tbucjnJSk8fRurQVx3E53RgP8
stIuVpBUKON+DxmHFY8XW2KawYBRktkN9QMwyZxlRutmT8ieN+AbvUNNdadTKTxH
5FOYrX0cTl39BoaG8lDxnOV+rgvpBkTIZ8MGgUnxMblXRyX+LGym88YS370Hcjim
/JIEHoHe8u6lZ+8Sa5unQ94cUJsZf9UHd7OhtSwif1dTTVsaz3WOtG1MsDA0DHuK
hOTGS1K4PDdipZ/GKTWdqnWlM30Wx5mnf0jtbg2FcG5Vkw2G9hg7PSC4WIKamVE0
IMMeUynexVIh3bUAEQEAAbQ4RmFyYWRheSwgSW5jLiAoaHR0cHM6Ly9mYXJhZGF5
LmFpKSA8aW5jb21pbmdAZmFyYWRheS5haT6JAdIEEwEIADwWIQRy4r9K+452dszO
IcabKbI+OQVBxwUCYbJi0AIbAwULCQgHAgMiAgEGFQoJCAsCBBYCAwECHgcCF4AA
CgkQmymyPjkFQcfd0Qv/SSLOFmOPNZDauYOUIsuAaJ8JFYMkMQH/WyacoqxtzMja
2dqK3/UMISlh4NvlNNgMY5Jyk4inEywpSoUBTKM4Ag2XpIEq4oLsAYgm+Ad8T5tu
8WWChxLjT99XNhqp4/7OZWMVaiWzG3yyhnIBdLk+GGNHTIAttvfxrJeqXxiJzWdQ
lwB3MMRR3FUKCgwDoBUaXKtY4vR1XBwHUClfC78tlWQRAiRMzGs9NNtQdafZoVEK
L12GnyayzL8w9VlILDPFfer0J+JwOoJvOiohiFXK7ONstwIevZwR5y41iJ5HCK9T
MqxiY3Jv/9npmSecPPZbdsNe5UwKQYwLC+8RueE8O4SpT33CNtUXPWVTYwiaAGwO
1QQIEhCAC4o4cxMUWADeaoQeLiVEeVmtD4nAZe788FUJeOcHy4XMV/rXVQ0HwUn/
zJ0vofHolibZnlvCpZrR60hMw6tQqmdaNyq9Co9ZjyURjUwbhnru0sXXXwE45pyd
yLbNDlUt5TFAjuRLuM+nuQGNBGGyYtABDADQo9Lg0D8X8rrYqlLvLCB2yxZGZ9h1
Lq/FyiXi2UFzaBgnJm3CKXA0M49Qt8AYtb/4ytsJyT+xe4d9WHsGnwEPQNjVrb/M
sJqLHUYfosk65kcrBg3kcbvZw+9HAWP5+Ah00BO93B84fcawWMOGtLh5TkTxTQ8p
8Kah80Jcu8yithBe+HdNZwzvcCxGKBVyPedK7uAtXOgyP0ZCg5o5B50gPgG5hTmv
yS2XgyUHCVj0yTOK57M9A3zlHVjF9ZgzFxfPrt8KaVRFySKI60S/HUVLu9Z55UKY
YzWYq1j6kwFfKdoDNKxLgGx4yzAmO5WY0Oc5DMc2HSSr0kgGM1TC9ISgsfcR9+pn
/+eRpQEkn6baA88oZ11NzseKUnMXcBb7R5D0HxG3lrzn1dbdubiqTXXYb1MY0Zmo
yzudyDmzaUqeiQOfbVnuXcCBKEff78AsyPccTVbU2GDbUn1m0s7z3wfbfU1Dz7vZ
0r4E85j2TeikhLPw+1DPhQbAeNbmGhFGyVkAEQEAAYkBtgQYAQgAIBYhBHLiv0r7
jnZ2zM4hxpspsj45BUHHBQJhsmLQAhsMAAoJEJspsj45BUHHbMsMAKFLJDRDRek5
Nf92uIwIzjYVxclRfR/rdtflUTk4wQ3x7rg0DgPR27vgIqRdtm5OMCaFX8lIsKxb
sBacmgiQE2svnTPQvqN+svSdX4aJYSbzZuQJOIDds1eJf+g+m/+Ia951NY3CH3Ds
AEJ45L2wOMuPWhjDFzPR92tNNp73t6guZ19XxVhjWDic3BTiWIsenImk256JHxXk
rJn6c6cY6SyckrLD09B9gllZoYK50nsEymV4WwZ65LPwCZk7Sd4wEkIIYc1vEaSl
YKr4BPcuIiwF5zSb7pfzQPtNgqsH1nQfxW9lY4//6m6jTEqBQXLagLzz0k29WzOL
XNUMhnyLjNGNwb9d7wL1XAD6sd8Xd9825/BV6YoeXBZ8heVJVQlQHCd37J2J8TsE
5lw+Q5EETFSVp+7W8gFuBLf9jbbhr1vNP3PkzhnszD6QD9TfMu7DzbJTkWui1Ddi
io2xZTPmm58zXxg0GWELEmBVwJq5R6th0FMMxePv+3RswiMvr+EVlw==
=DKhY
-----END PGP PUBLIC KEY BLOCK-----
Faraday's IP allowlist
When creating a connection in Faraday, be sure that the below list of IP addresses are added to your organization's allowlist, otherwise any connection you configure may fail or go stale.
- 34.86.175.54
- 34.86.252.230
- 34.145.239.81
- 35.245.199.181
- 52.22.91.248
- 52.23.137.21
- 52.204.223.208
- 52.204.228.32
- 52.204.230.227
Deleting or archiving a connection
Before deleting a connection, ensure that all resources using it, such as an event stream, any cohorts using those event streams, any outcomes using those cohorts, etc, are no longer using it. Once there are no other resources using the connection, you can safely delete it.
- Dashboard: click the ... menu on the far right of the connection you'd like to delete or archive (or the upper right while viewing a specific one), then click the relevant option.
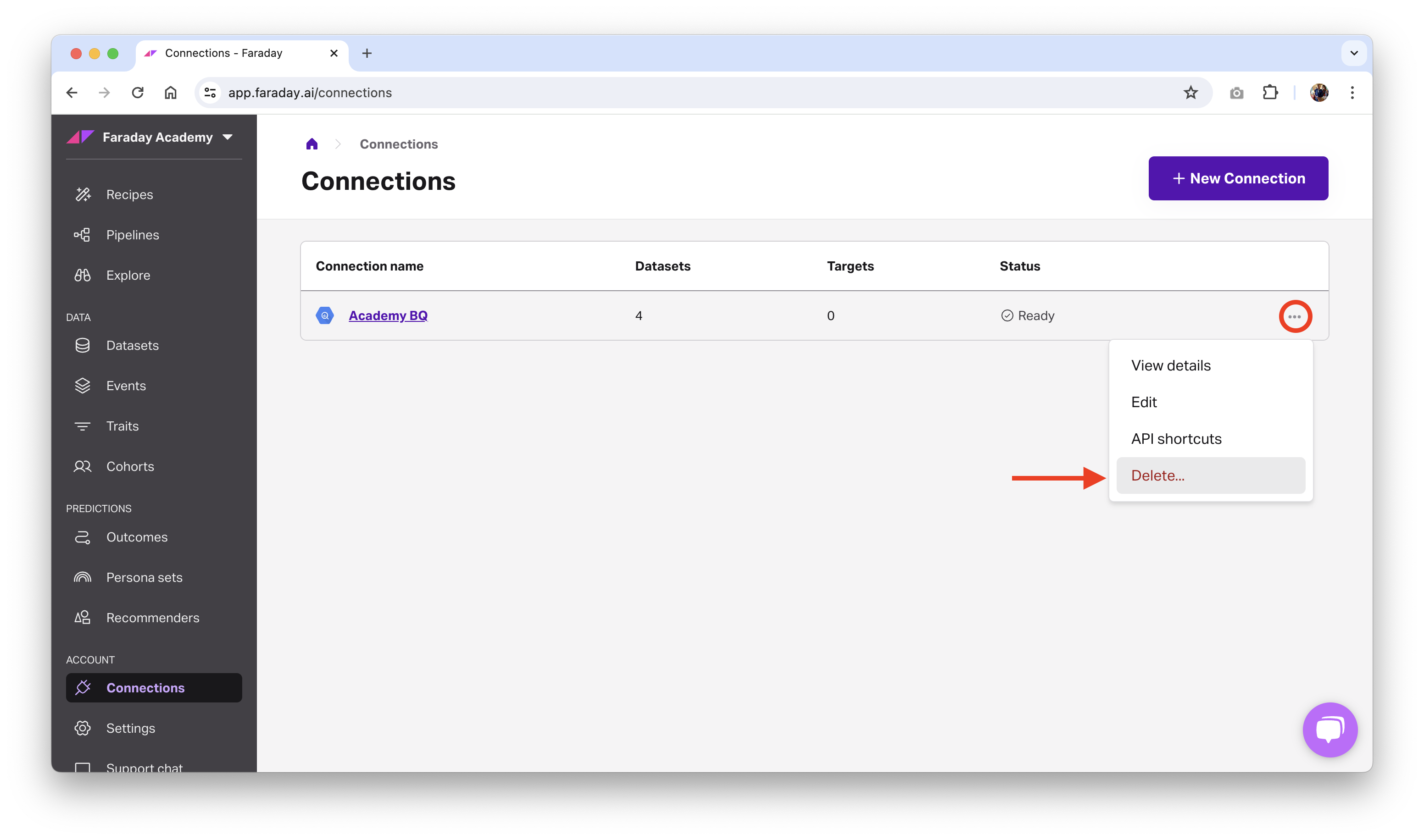
- API: use the delete connection or archive connection API requests.
📘Deleting and archiving resources
See object preservation for more info on deleting and archiving resources.
Saving time and money with primary keys and incremental loading
Faraday supports primary keys and incremental loading for all of its database connections. There are many advantages to this:
- Save thousands of dollars per month in data query and transfer costs for large tables.
- Reduce load on your database or data warehouse.
- Ensure that duplicate rows are not created when a single column changes in an existing row.
In order to get these benefits, we recommend that you set, on all datasets:
- Primary key (known as
upsert_columnsin the API): to the primary key of the table. For example,customer_id,LeadId,eventIdetc. In some cases, it may be an email column. If you don't have a single column that is unique, then you can use the API to submit a composite primary key. Contact support if you have questions about composite keys. - Incremental column: to the modification timestamp of the table. For example,
updated_at,LastModifiedAt,system_timestamp, etc.
If you set these, then Faraday will only check new and updated records when it checks a dataset. When there are a billion records in a table–but only a million are added or changed each day–this can be a huge savings. This also makes the dataset more reliable.